# Import Packages
import math
import csv
import earthaccess
import numpy as np
import pandas as pd
import geopandas as gpd
import rioxarray as rxr
import xarray as xr
import hvplot.xarray
import holoviews as hv
import geoviews as gv
import cartopy.crs as ccrs
from vitals.emit_tools import emit_xarray, ortho_xrEMIT L2A Reflectance Fundamentals
Summary
This notebook will explain how to access Earth Surface Mineral Dust Source Investigation (EMIT) data programmatically using the earthaccess Python library. earthaccess is a useful Python library that facilitates finding and downloading or streaming data over HTTPS or s3. earthaccess searches NASA’s Common Metadata Repository (CMR), a metadata system that catalogs Earth Science data and associated metadata records, then can be used to download granules or generate lists of granule search result URLs. After accessing the data, we will open visualize the EMIT L2A Reflectance Data (EMITL2ARFL), and extract spectral values for a series of points using an interactive plot.
Background
The EMIT instrument is an imaging spectrometer that measures light in visible and infrared wavelengths. These measurements display unique spectral signatures that correspond to the composition on the Earth’s surface. The EMIT mission focuses specifically on mapping the composition of minerals to better understand the effects of mineral dust throughout the Earth system and human populations now and in the future. More details about EMIT and its associated products can be found in the README.md and on the EMIT website.
The L2A Reflectance Product contains estimated surface reflectance. Surface reflectance is the fraction of incoming solar radiation reflected Earth’s surface. Materials reflect proportions of radiation differently based upon their chemical composition. This means that reflectance information can be used to determine the composition of a target. In this guide you will learn how to plot a band from the L2A reflectance spatially and look at the spectral curve associated with individual pixels.
Requirements
- A NASA Earthdata Login account is required.
Learning Objectives
- How to find EMIT data using
earthaccess - How to open an EMIT
.ncfile as anxarray.Dataset - How to work with EMIT L2A Reflectance data
- How to mask and quality filter EMIT L2A Reflectance data
Setup
Import the required Python libraries.
Note that we we are importing a local module for handling EMIT data called emit_tools.
Authentication
earthaccess creates and leverages Earthdata Login tokens to authenticate with NASA systems. Earthdata Login tokens expire after a month. To retrieve a token from Earthdata Login, you can either enter your username and password each time you use earthaccess, or use a .netrc file. A .netrc file is a configuration file that is commonly used to store login credentials for remote systems. If you don’t have a .netrc or don’t know if you have one or not, you can use the persist argument with the login function below to create or update an existing one, then use it for authentication.
If you do not have an Earthdata Account, you can create one here.
auth = earthaccess.login(persist=True)Searching for Collections
The EMIT mission produces several collections or datasets available via the NASA Earthdata cloud archive.
To view what’s available, we can use the search_datasets function and with the keyword argument.
# Retrieve Collections
collections = earthaccess.search_datasets(keyword='EMIT')
# Print Quantity of Results
print(f'Collections found: {len(collections)}')Collections found: 70If you print the collections object you can explore all of the json metadata.
# Print collections
# collectionsWe can also create a list of the short-name, concept-id, and version of each result collection using list comprehension. These fields are important for specifying and searching for data within collections.
collections_info = [
{
'short_name': c['umm']['ShortName'],
'collection_concept_id': c['meta']['concept-id'],
'version': c['umm']['Version'],
'entry_title': c['umm']['EntryTitle']
}
for c in collections
]
pd.set_option('display.max_colwidth', 150)
collections_info = pd.DataFrame(collections_info)
collections_info| short_name | collection_concept_id | version | entry_title | |
|---|---|---|---|---|
| 0 | EMITL2ARFL | C2408750690-LPCLOUD | 001 | EMIT L2A Estimated Surface Reflectance and Uncertainty and Masks 60 m V001 |
| 1 | EMITL1BRAD | C2408009906-LPCLOUD | 001 | EMIT L1B At-Sensor Calibrated Radiance and Geolocation Data 60 m V001 |
| 2 | EMITL2BMIN | C2408034484-LPCLOUD | 001 | EMIT L2B Estimated Mineral Identification and Band Depth and Uncertainty 60 m V001 |
| 3 | EMITL2BCH4ENH | C3242680113-LPCLOUD | 002 | EMIT L2B Methane Enhancement Data 60 m V002 |
| 4 | EMITL4ESM | C2408755900-LPCLOUD | 001 | EMIT L4 Earth System Model Products V001 |
| ... | ... | ... | ... | ... |
| 65 | Aqua_AMSR-E_L1B_TB | C2698130454-JAXA | NA | Aqua/AMSR-E L1B Brightness Temperature |
| 66 | TG07_Soil-Atmosphere_Flux_Km83_926 | C2777750487-ORNL_CLOUD | 1 | LBA-ECO TG-07 Trace Gas Fluxes, Undisturbed and Logged Sites, Para, Brazil: 2000-2002 |
| 67 | bvoc_flux_759 | C2780105326-ORNL_CLOUD | 1 | SAFARI 2000 BVOC Measurements at Skukuza and Maun Flux Towers, Wet Season 2001 |
| 68 | K011_2000_2001_NZ_1 | C1214593941-SCIOPS | Not provided | The concentration of combustion engine particulates, the organic fraction of the particulates and the sources of the particulates identified by is... |
| 69 | VATECH_VAdust | C2231548569-CEOS_EXTRA | Not provided | Dust Deposition in Southern Nevada and California |
70 rows × 4 columns
The collection concept-id is the best way to search for data within a collection, as this is unique to each collection. The short-name can be used as well, however the version should be passed as well as there can be multiple versions available with the same short name. After finding the collection you want to search, you can use the concept-id to search for granules within that collection.
Searching for Granules
A granule can be thought of as a unique spatiotemporal grouping within a collection. To search for granules, we can use the search_data function from earthaccess and provide the arguments for our search. Its possible to specify search products using several criteria shown in the table below:
| dataset origin and location | spatio temporal parameters | dataset metadata parameters |
|---|---|---|
| archive_center | bounding_box | concept_id |
| data_center | temporal | entry_title |
| daac | point | granule_name |
| provider | polygon | version |
| cloud_hosted | line | short_name |
For this example we will search for the EMIT L2A Surface Reflectance using a bounding box, temporal parameters, and add a cloud_cover parameter. Note that not all datasets have cloud cover information in their metadata, so this parameter may not work for all datasets.
# Boulder CO Area Bounding Box
bbox = (-105.301, 39.957, -105.178, 40.094)
bbox(-105.301, 39.957, -105.178, 40.094)Pass the bbox Python variable to the bounding_box argument, then enter a start and end date for the temporal argument minimum and maximum cloud_cover as Python tuples.
results = earthaccess.search_data(
short_name='EMITL2ARFL',
bounding_box=bbox,
temporal=('2023-06-01','2023-09-30'),
cloud_cover=(0,50)
)
print(f"Granules Found: {len(results)}")Granules Found: 2C:\Users\ebolch\AppData\Local\miniforge3\envs\lpdaac_vitals\Lib\site-packages\earthaccess\results.py:348: FutureWarning: As of version 1.0, `DataGranule.size` will be accessed as an attribute; e.g. use `DataCollection.size` **not** `DataCollection.size()`
self["size"] = self.size()We can preview our results by printing a single one.
print(results[0])Collection: {'ShortName': 'EMITL2ARFL', 'Version': '001'}
Spatial coverage: {'HorizontalSpatialDomain': {'Geometry': {'GPolygons': [{'Boundary': {'Points': [{'Longitude': -105.92611694335938, 'Latitude': 40.60380172729492}, {'Longitude': -106.3302001953125, 'Latitude': 39.925174713134766}, {'Longitude': -105.47183227539062, 'Latitude': 39.414066314697266}, {'Longitude': -105.0677490234375, 'Latitude': 40.09269332885742}, {'Longitude': -105.92611694335938, 'Latitude': 40.60380172729492}]}}]}}}
Temporal coverage: {'RangeDateTime': {'BeginningDateTime': '2023-06-25T17:08:14Z', 'EndingDateTime': '2023-06-25T17:08:26Z'}}
Size(MB): 3581.195469856262
Data: ['https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170814_2317611_005/EMIT_L2A_RFL_001_20230625T170814_2317611_005.nc', 'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170814_2317611_005/EMIT_L2A_RFLUNCERT_001_20230625T170814_2317611_005.nc', 'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170814_2317611_005/EMIT_L2A_MASK_001_20230625T170814_2317611_005.nc']C:\Users\ebolch\AppData\Local\miniforge3\envs\lpdaac_vitals\Lib\site-packages\earthaccess\results.py:375: FutureWarning: As of version 1.0, `DataGranule.size` will be accessed as an attribute; e.g. use `DataCollection.size` **not** `DataCollection.size()`
Size(MB): {self.size()}Use data_links() convenience function to extract the data links for all of the granules. In this case there are multiple files associated with a single granule.
emit_results_urls = [granule.data_links(access="external") for granule in results]
emit_results_urls[:2][['https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170814_2317611_005/EMIT_L2A_RFL_001_20230625T170814_2317611_005.nc',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170814_2317611_005/EMIT_L2A_RFLUNCERT_001_20230625T170814_2317611_005.nc',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170814_2317611_005/EMIT_L2A_MASK_001_20230625T170814_2317611_005.nc'],
['https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170826_2317611_006/EMIT_L2A_RFL_001_20230625T170826_2317611_006.nc',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170826_2317611_006/EMIT_L2A_RFLUNCERT_001_20230625T170826_2317611_006.nc',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170826_2317611_006/EMIT_L2A_MASK_001_20230625T170826_2317611_006.nc']]Flatten our list of lists into a single list.
url_list = [url for urls in emit_results_urls for url in urls]
url_list['https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170814_2317611_005/EMIT_L2A_RFL_001_20230625T170814_2317611_005.nc',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170814_2317611_005/EMIT_L2A_RFLUNCERT_001_20230625T170814_2317611_005.nc',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170814_2317611_005/EMIT_L2A_MASK_001_20230625T170814_2317611_005.nc',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170826_2317611_006/EMIT_L2A_RFL_001_20230625T170826_2317611_006.nc',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170826_2317611_006/EMIT_L2A_RFLUNCERT_001_20230625T170826_2317611_006.nc',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170826_2317611_006/EMIT_L2A_MASK_001_20230625T170826_2317611_006.nc']Working with EMIT Data
EMIT collections and their associated granules are archived and distributed from NASA’s Earthdata Cloud. Because of this, data assets/files can be accessed in a variety of ways. Data distributed from Earthdata Cloud can be:
Downloaded – This has been a supported option since the inception of NASA’s DAACs. Users can use the data link(s) to download files to their local working environment. This method works in both cloud and non-cloud environments.
Streamed – Streaming enables on-the-fly reading of remote files (i.e., files not saved locally). However, the accessed data must fit into the workspace’s memory. Streaming works in both cloud and non-cloud environments. Streaming data stored in the cloud without downloading is called in-place access or direct S3 access. this is only available when working in a cloud environment deployed in AWS us-west-2.
Downloading Data
The download() function from earthaccess can be used to efficiently download the data links from a earthaccess search results. A list of URLs can also be passed to the function. The convenient part of using the download() function is that authentication is taken care of on behalf of the user.
Download earthaccess search results
# earthaccess.download(results, local_path='../data/')Download from URL list
#earthaccess.download(url_list, local_path='../data/')Streaming Data
Data in NASA Earthdata Cloud can be read into the workspace by streaming the data, that is, no download is required. Here we will assign a single URL for EMIT reflectance and for the mask layer from our url_list to read in and explore.
emit_rfl = url_list[0]
emit_rfl'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170814_2317611_005/EMIT_L2A_RFL_001_20230625T170814_2317611_005.nc'emit_qa = url_list[2]
emit_qa'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/EMITL2ARFL.001/EMIT_L2A_RFL_001_20230625T170814_2317611_005/EMIT_L2A_MASK_001_20230625T170814_2317611_005.nc'To access data from NASA, you’ll need to provide your Earthdata Login credentials. When streaming this can best be done using the token or cookies set up by the earthaccess library. Since we’ve already logged in, we can start an fsspec session to manage our connection to a remote file, including sending credentials. This allows other libraries to work with a URL as if it is a local file.
# Get HTTPS Session using Earthdata Login Info
fs = earthaccess.get_fsspec_https_session()
# Use the session (i.e., fs) to connect to the file
emit_fp = fs.open(emit_rfl)
emit_qa_fp = fs.open(emit_qa)We now have an authenticated connection to the data links. We can now start exploring these data.
Opening and Exploring EMIT Reflectance Data
EMIT L2A Reflectance Data are distributed in a non-orthocorrected spatially raw NetCDF4 (.nc) format consisting of the data and its associated metadata. Inside the L2A Reflectance .nc file there are 3 groups. Groups can be thought of as containers to organize the data.
- The root group that can be considered the main dataset contains the reflectance data described by the downtrack, crosstrack, and bands dimensions.
- The
sensor_band_parametersgroup containing the wavelength center and the full-width half maximum (FWHM) of each band.
- The
locationgroup contains latitude and longitude values at the center of each pixel described by the crosstrack and downtrack dimensions, as well as a geometry lookup table (GLT) described by the ortho_x and ortho_y dimensions. The GLT is an orthorectified image (EPSG:4326) consisting of 2 layers containing downtrack and crosstrack indices. These index positions allow us to quickly project the raw data onto this geographic grid.
To work with the EMIT data, we will use the emit_tools module. There are other ways to work with the data and a more thorough explanation of the emit_tools in the EMIT-Data-Resources Repository.
Open the example EMIT scene using the emit_xarray function. In this step we will use the ortho=False argument (default) read in the data in its source non-orthocorrected form.
# Load the data to speed up future cells
emit_ds = emit_xarray(emit_fp, ortho=False).load()
emit_ds<xarray.Dataset> Size: 2GB
Dimensions: (downtrack: 1280, crosstrack: 1242, wavelengths: 285,
ortho_y: 1970, ortho_x: 2329)
Coordinates:
* downtrack (downtrack) int64 10kB 0 1 2 3 4 ... 1276 1277 1278 1279
* crosstrack (crosstrack) int64 10kB 0 1 2 3 4 ... 1238 1239 1240 1241
lon (downtrack, crosstrack) float64 13MB -106.3 ... -105.1
lat (downtrack, crosstrack) float64 13MB 39.93 39.93 ... 40.09
elev (downtrack, crosstrack) float64 13MB 2.358e+03 ... 1.51...
* wavelengths (wavelengths) float32 1kB 381.0 388.4 ... 2.493e+03
fwhm (wavelengths) float32 1kB 8.415 8.415 ... 8.807 8.809
good_wavelengths (wavelengths) float32 1kB 1.0 1.0 1.0 1.0 ... 1.0 1.0 1.0
glt_x (ortho_y, ortho_x) float64 37MB 0.0 0.0 0.0 ... 0.0 0.0
glt_y (ortho_y, ortho_x) float64 37MB 0.0 0.0 0.0 ... 0.0 0.0
Dimensions without coordinates: ortho_y, ortho_x
Data variables:
reflectance (downtrack, crosstrack, wavelengths) float32 2GB 0.0240...
Attributes: (12/39)
ncei_template_version: NCEI_NetCDF_Swath_Template_v2.0
summary: The Earth Surface Mineral Dust Source ...
keywords: Imaging Spectroscopy, minerals, EMIT, ...
Conventions: CF-1.63
sensor: EMIT (Earth Surface Mineral Dust Sourc...
instrument: EMIT
... ...
spatialResolution: 0.000542232520256367
spatial_ref: GEOGCS["WGS 84",DATUM["WGS_1984",SPHER...
geotransform: [-1.06330989e+02 5.42232520e-04 -0.00...
day_night_flag: Day
title: EMIT L2A Estimated Surface Reflectance...
granule_id: EMIT_L2A_RFL_001_20230625T170814_23176...Since the wavelengths coordinate variable is indexed, we can use sel() functions to filter for specific wavelength values from our EMIT datacube, then visualize using hvplot.image()
# Select a band @ 850nm
rfl_850 = emit_ds['reflectance'].sel(wavelengths=850, method='nearest')
# Plot - Note we flip the y axis, so (0,0) is top left corner
rfl_850.hvplot.image(rasterize=True, dynamic=False, cmap='viridis',
aspect='equal',
frame_height=405,
fontscale=2).opts(title=f"{rfl_850.wavelengths:.3f} {rfl_850.wavelengths.units}", invert_yaxis=True)Note the orientation of the plotted image. Remember this is not orthocorrected and thus is not north up. You may notice that EMIT radiance and reflectance scenes rows of missing data in some scenes. This is due to EMIT’s on-board cloud filtering. Additionally, filtering can be applied using the mask layer (example later in this exercise).
Create an orthocorrected image of our data using the ortho_xr() function from the emit_tools module.
emit_ds = ortho_xr(emit_ds)
emit_ds<xarray.Dataset> Size: 5GB
Dimensions: (latitude: 1970, longitude: 2329, wavelengths: 285)
Coordinates:
* latitude (latitude) float64 16kB 40.54 40.54 40.54 ... 39.48 39.48
* longitude (longitude) float64 19kB -106.3 -106.3 ... -105.1 -105.1
elev (latitude, longitude) float32 18MB -9.999e+03 ... -9.99...
* wavelengths (wavelengths) float32 1kB 381.0 388.4 ... 2.493e+03
fwhm (wavelengths) float32 1kB 8.415 8.415 ... 8.807 8.809
good_wavelengths (wavelengths) float32 1kB 1.0 1.0 1.0 1.0 ... 1.0 1.0 1.0
spatial_ref int64 8B 0
Data variables:
reflectance (latitude, longitude, wavelengths) float32 5GB -9.999e+...
Attributes: (12/39)
ncei_template_version: NCEI_NetCDF_Swath_Template_v2.0
summary: The Earth Surface Mineral Dust Source ...
keywords: Imaging Spectroscopy, minerals, EMIT, ...
Conventions: CF-1.63
sensor: EMIT (Earth Surface Mineral Dust Sourc...
instrument: EMIT
... ...
spatialResolution: 0.000542232520256367
spatial_ref: GEOGCS["WGS 84",DATUM["WGS_1984",SPHER...
geotransform: [-1.06330989e+02 5.42232520e-04 -0.00...
day_night_flag: Day
title: EMIT L2A Estimated Surface Reflectance...
granule_id: EMIT_L2A_RFL_001_20230625T170814_23176...During the orthorectification process we introduce fill values (-9999). To make a better visual, we can assign these to np.nan. At the same time we can also utilize the good_wavelengths flag from the sensor_band_parameters group to mask out bands where water absorption features were assigned a value of -0.01 reflectance. Typically data around 1320-1440 nm and 1770-1970 nm are noisy due to the moisture present in the atmosphere; therefore, these spectral regions offer little information about targets and can be excluded from calculations.
emit_ds['reflectance'].data[:,:,emit_ds['good_wavelengths'].data==0] = np.nan
emit_ds['reflectance'].data[emit_ds['reflectance'].data == -9999] = np.nan# Select Band
rfl_850 = emit_ds['reflectance'].sel(wavelengths=850, method='nearest')
# Plot
rfl_850.hvplot.image(rasterize=True, dynamic=False, cmap='viridis',
geo=True,
tiles='ESRI',
crs='EPSG:4326',
frame_width=720,
frame_height=405,
alpha=0.7,
fontscale=2).opts(title=f"{rfl_850.wavelengths:.3f} {rfl_850.wavelengths.units}",
xlabel='Longitude',ylabel='Latitude')We now have a orthorectified image that is north up!
Plotting Spectra
Similar to selecting a wavelength, we can select the spectra of an individual pixel closest to a specified latitude and longitude we want using the sel function from xarray. First grab the center coordinates of the scene to use as an example.
# Retrieve center pixel coordinates
scene_center = emit_ds.latitude.values[int(len(emit_ds.latitude)/2)],emit_ds.longitude.values[int(len(emit_ds.longitude)/2)]
scene_center(np.float64(40.00857386925845), np.float64(-105.69955918991546))Now select and plot using hvplot.
# Extract a single point
point = emit_ds.sel(latitude=scene_center[0],longitude=scene_center[1], method='nearest')
# Plot
point.hvplot.line(y='reflectance',
x='wavelengths',
color='black').opts(title=f'Latitude = {point.latitude.values.round(3)}, Longitude = {point.longitude.values.round(3)}')We can also plot individual bands spatially by selecting a wavelength, then plotting. Select the band with a wavelengths of 850 nm and plot it using ESRI imagery as a basemap to get a better understanding of where the scene was acquired.
Applying Quality Masks to EMIT Data
The EMIT L2A Mask file contains some bands that are direct masks (Cloud, Dilated, Cirrus, Water, Spacecraft), and some (AOD550 and H2O (g cm-2)) that contain information calculated during the L2A reflectance retrieval. These may be used as additional screening, depending on the application.
Note: It is more memory efficient to apply the mask before orthorectifying.
emit_mask = emit_xarray(emit_qa_fp, ortho=True)
emit_mask<xarray.Dataset> Size: 826MB
Dimensions: (latitude: 1970, longitude: 2329, mask_bands: 8,
packed_wavelength_bands: 36)
Coordinates:
* latitude (latitude) float64 16kB 40.54 40.54 40.54 ... 39.48 39.48 39.48
* longitude (longitude) float64 19kB -106.3 -106.3 -106.3 ... -105.1 -105.1
elev (latitude, longitude) float32 18MB -9.999e+03 ... -9.999e+03
* mask_bands (mask_bands) object 64B 'Cloud flag' ... 'Aggregate Flag'
spatial_ref int64 8B 0
Dimensions without coordinates: packed_wavelength_bands
Data variables:
mask (latitude, longitude, mask_bands) float32 147MB -9.999e+03 ....
band_mask (latitude, longitude, packed_wavelength_bands) float32 661MB ...
Attributes: (12/40)
ncei_template_version: NCEI_NetCDF_Swath_Template_v2.0
summary: The Earth Surface Mineral Dust Source ...
keywords: Imaging Spectroscopy, minerals, EMIT, ...
Conventions: CF-1.63
sensor: EMIT (Earth Surface Mineral Dust Sourc...
instrument: EMIT
... ...
spatial_ref: GEOGCS["WGS 84",DATUM["WGS_1984",SPHER...
geotransform: [-1.06330989e+02 5.42232520e-04 -0.00...
day_night_flag: Day
title: EMIT L2A Masks 60 m V001
granule_id: EMIT_L2A_MASK_001_20230625T170814_2317...
Orthorectified: TrueList the quality flags contained in the mask_bands dimension.
emit_mask.mask_bands.data.tolist()['Cloud flag',
'Cirrus flag',
'Water flag',
'Spacecraft Flag',
'Dilated Cloud Flag',
'AOD550',
'H2O (g cm-2)',
'Aggregate Flag']As mentioned, we will use the Dilated Cloud Flag. Select that band with the sel function as we did for wavelengths before.
emit_cloud_mask = emit_mask.sel(mask_bands='Dilated Cloud Flag')
# mask fill values
emit_cloud_mask['mask'].data[emit_cloud_mask['mask'].data == -9999] = np.nanNow we can visualize our aggregate quality mask. You may have noticed before that we added a lot of parameters to our plotting function. If we want to consistently apply the same formatting for multiple plots, we can add those arguments to a dictionary that we can unpack into hvplot functions using **.
Create two dictionaries with plotting options.
size_opts = dict(frame_height=405, frame_width=720, fontscale=2)
map_opts = dict(geo=True, crs='EPSG:4326', alpha=0.7, xlabel='Longitude',ylabel='Latitude')emit_cloud_mask.hvplot.image(rasterize=True, dynamic=False, cmap='viridis', tiles='ESRI', **size_opts, **map_opts)Values of 1 in the mask indicate areas to omit. Apply the mask to our EMIT Data by assigning values where the mask.data == 1 to np.nan
emit_ds.reflectance.data[emit_cloud_mask.mask.data == 1] = np.nanWe can confirm our masking worked with a spatial plot.
emit_layer_filtered_plot = emit_ds.sel(wavelengths=850, method='nearest').hvplot.image(rasterize=True, dynamic=False, cmap='viridis',tiles='ESRI',**size_opts, **map_opts)
emit_layer_filtered_plotInteractive Spectral/Spatial Plots
Combining the Spatial and Spectral information into a single visualization can be a powerful tool for exploring and inspecting imaging spectroscopy data. Using the streams module from Holoviews we can link a spatial map to a plot of spectra.
We could plot a single band image as we previously have, but using a multiband image, like an RGB may help infer what targets we’re examining. Build an RGB image following the steps below.
Select bands to represent red (650 nm), green (560 nm), and blue (470 nm) by finding the nearest to a wavelength chosen to represent that color.
emit_rgb = emit_ds['reflectance'].sel(wavelengths=[650, 560, 470], method='nearest')We may need to adjust balance the brightness of the selected wavelengths to make a prettier map. This will not affect the data, just the visuals. To do this we will use the function below. We can change the bright argument to increase or decrease the brightness of the scene as a whole. A value of 0.2 usually works pretty well.
def gamma_adjust(rgb_da, bright=0.3):
"""
Adjust gamma across all bands in the RGB dataset.
"""
array = rgb_da.data
# Mask nan and negative values
invalid = np.isnan(array) | (array < 0)
valid = ~invalid
# Calculate gamma based on the mean of valid values
mean_valid = np.nanmean(array[valid])
gamma = math.log(bright) / math.log(mean_valid)
# Apply scaling and clip
scaled = np.full_like(array, np.nan)
scaled[valid] = np.power(array[valid], gamma)
rgb_da.data = np.clip(scaled, 0, 1)
return rgb_daemit_rgb = gamma_adjust(emit_rgb)Now that we have an RGB dataset, we can use that to create a spatial plot, and data selected by clicking on that ‘map’ can be inputs for a function to return values from the full dataset at that latitude and longitude location using the cell below. To visualize the spectral and spatial data side-by-side, we use the Point Draw tool from the holoviews library.
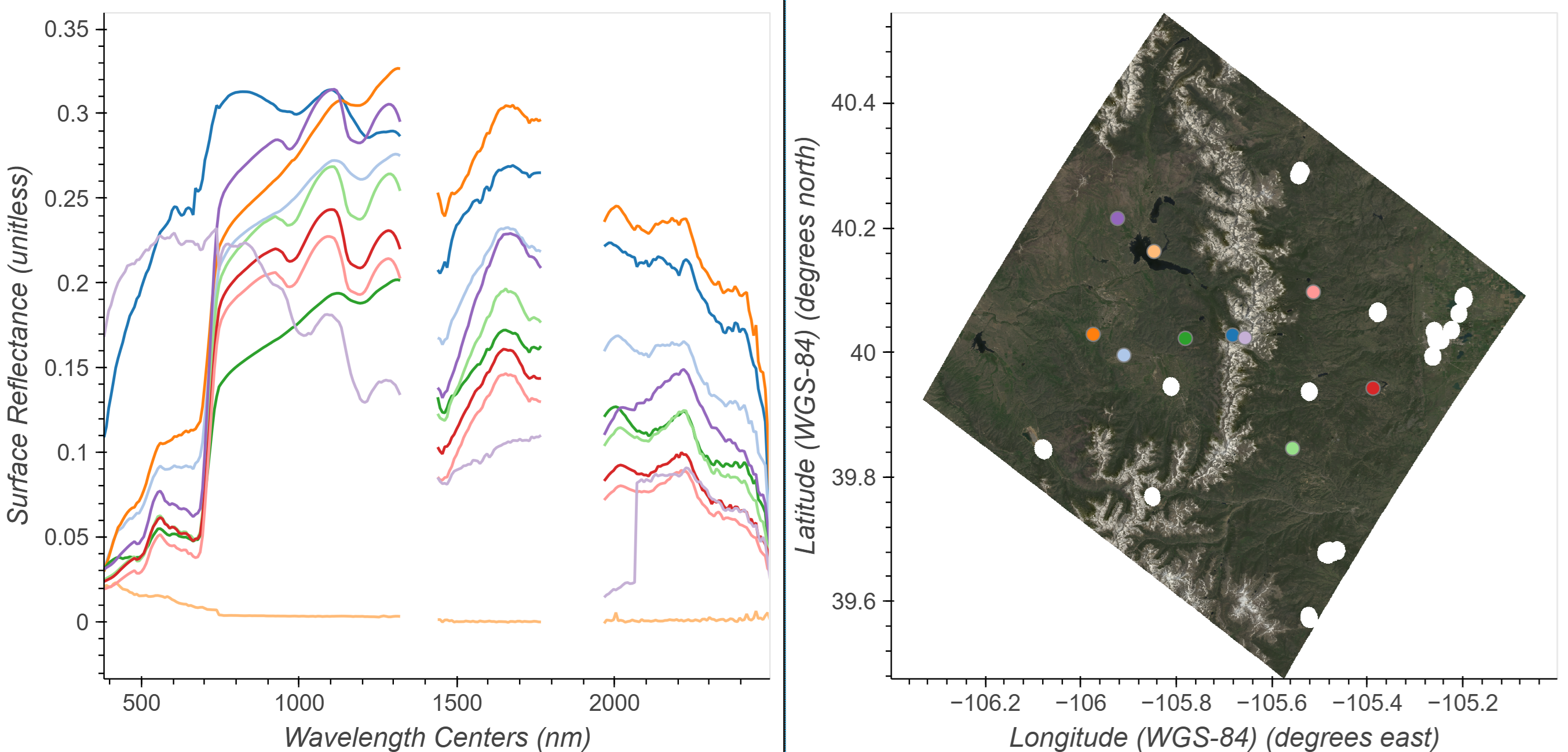
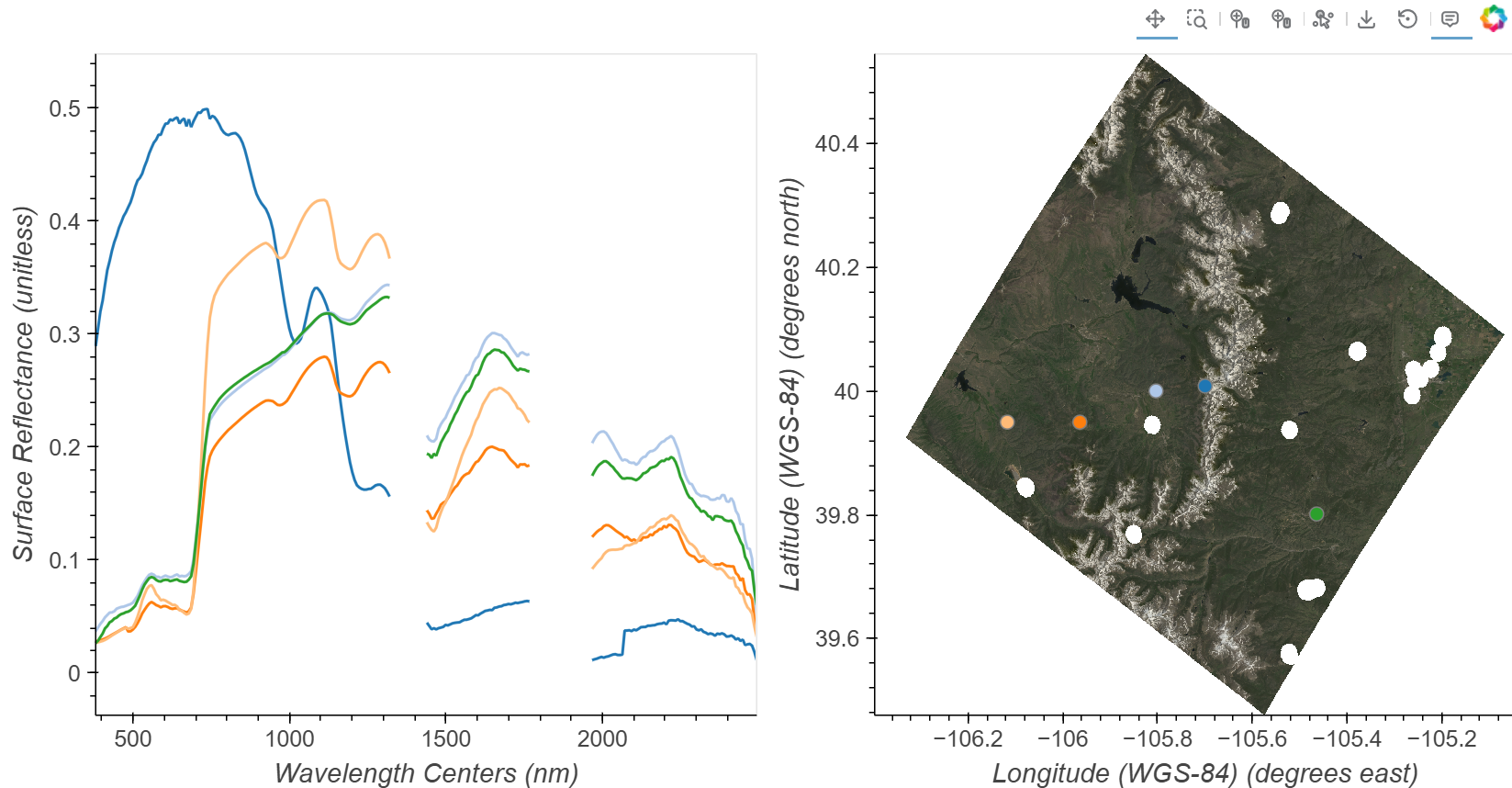
Define a limit to the quantity of points and spectra we will plot, a list of colors to cycle through, and an initial point. Then use the input from the Tap function to provide clicked x and y positions on the map and use these to retrieve spectra from the dataset at those coordinates.
Click in the RGB image to add spectra to the plot. You can also click and hold the mouse button then drag previously placed points. To remove a point click and hold the mouse button down, then press the backspace key.
# Interactive Spectral/Spatial Plotting
# Modified from https://github.com/auspatious/hyperspectral-notebooks/blob/main/03_EMIT_Interactive_Points.ipynb
# Starting Point from center pixel
x_start = scene_center[1]
y_start = scene_center[0]
# Set Point Limit
POINT_LIMIT = 10
# Set up Color Cycling
color_cycle = hv.Cycle('Category20')
# Define initial point and spatial plot
first_point = ([x_start], [y_start], [0])
points = gv.Points(first_point, kdims=['longitude','latitude'], vdims='id', crs=ccrs.PlateCarree())
# Define Point Draw Plot
points_stream = hv.streams.PointDraw(
data=points.columns(),
source=points,
drag=True,
num_objects=POINT_LIMIT,
styles={'fill_color': color_cycle.values[:POINT_LIMIT], 'line_color': 'gray'}
)
# RGB Plot without Basemap
rgb_map = emit_rgb.hvplot.rgb(x='longitude', y='latitude', bands='wavelengths',
frame_height=480, frame_width=480,
crs=ccrs.PlateCarree(),
title="Stretched RGB EMIT Image")
# Set up tap and point streams
posxy = hv.streams.PointerXY(source=rgb_map, x=x_start, y=y_start)
clickxy = hv.streams.Tap(source=rgb_map, x=x_start, y=y_start)
# Function to build spectral plot of clicked location to show on hover stream plot
def click_spectra(data):
coordinates = [c for c in zip(data['longitude'], data['latitude'])]
plots = {}
for i, coords in enumerate(coordinates):
x, y = coords
selected = emit_ds['reflectance'].sel(longitude=x, latitude=y, method="nearest")
plots[i] = (
selected.hvplot.line(
y="reflectance",
x="wavelengths",
label=f"{i}"
)
)
points_stream.data["id"][i] = i
return hv.NdOverlay(plots).opts(hv.opts.Curve(color=color_cycle))
# Function to provide hover spectra
def hover_spectra(x,y):
return emit_ds['reflectance'].sel(longitude=x,latitude=y,method='nearest').hvplot.line(y='reflectance',x='wavelengths',
color='black', frame_width=480)
# Define the Dynamic Maps
click_dmap = hv.DynamicMap(click_spectra, streams=[points_stream])
hover_dmap = hv.DynamicMap(hover_spectra, streams=[posxy])
# Plot the Map and Dynamic Map side by side
hv.Layout(hover_dmap*click_dmap + rgb_map * points).cols(2).opts(
hv.opts.Points(active_tools=['point_draw'], size=10, tools=['hover'], color='white', line_color='gray'),
hv.opts.Overlay(show_legend=False, show_title=False, fontscale=1.5, frame_height=480)
)
We can take these selected points and the corresponding reflectance spectra and save them as a .csv for later use.
Build a dictionary of the selected points and spectra, then export the spectra to a .csv file.
data = points_stream.data
wavelengths = emit_ds.wavelengths.values
rows = [["id", "longitude", "latitude"] + [str(i) for i in wavelengths]]
for p in zip(data['longitude'], data['latitude'], data['id']):
x, y, i = p
spectra = emit_ds.sel(longitude=x, latitude=y, method="nearest").reflectance.values
row = [i, x, y] + list(spectra)
rows.append(row)# Write points to csv
with open('../data/emit_l2a_rfl_click_data.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerows(rows)Contact Info:
Email: LPDAAC@usgs.gov
Voice: +1-866-573-3222
Organization: Land Processes Distributed Active Archive Center (LP DAAC)¹
Website: https://www.earthdata.nasa.gov/centers/lp-daac
¹Work performed under USGS contract 140G0126D0001 for NASA contract NNG14HH33I.