import earthaccess # needed to discover and download TEMPO data
import netCDF4 as nc # needed to read TEMPO data
import numpy as np
import matplotlib.pyplot as plt # needed to plot the resulting time series
import cartopy.crs as ccrs
import cartopy.feature as cfeatureDemonstration for working with TEMPO data via earthaccess
Overview
This notebook retrieves TEMPO data, inspects characteristics of the data such as array shapes and quality flags, and then creates a visualization of total column nitrogen dioxide concentrations.
Dataset Information
This notebook uses data from the Tropospheric Emissions: Monitoring of Pollution (TEMPO) instrument.
Prerequisites
A free(!) account at https://www.earthdata.nasa.gov/ is needed to login and download the appropriate files.
This notebook was last tested using Python 3.10.15, and requires these libraries:
1. Setup
2. Establish access to EarthData - Log in
If credentials are not already stored, earthaccess.login will prompt for EarthData login and password.
auth = earthaccess.login(persist=True)3. Search for TEMPO granules
First, we specify the data collection by name, a Point of Interest (POI), and a temporal range.
short_name = "TEMPO_NO2_L3" # collection name to search for in the EarthData
version = "V03"
# Point of interest: NASA Langley Research Center, HamptonVA, USA
# latitude 37.1036 deg, longitude -76.3868 deg
# POI_lat = 37.1036
# POI_lon = -76.3868
# generic location, somewhere in the middle of the USA
POI_lat = 38.0
POI_lon = -96.0
date_start = "2024-09-01 00:00:00"
date_end = "2024-09-01 23:59:59"Now we search for nitrogen dioxide (\(NO_2\)) data granules from TEMPO.
POI_results = earthaccess.search_data(
short_name=short_name,
version=version,
temporal=(date_start, date_end),
point=(POI_lon, POI_lat), # search by point of interest
)
print(len(POI_results))18dlat = 5.0 # deg
dlon = 6.0 # deg
bbox_results = earthaccess.search_data(
short_name=short_name,
version=version,
temporal=(date_start, date_end),
bounding_box=(
POI_lon - dlon,
POI_lat - dlat,
POI_lon + dlon,
POI_lat + dlat,
), # search by bounding box
)
print(len(bbox_results))184. Examine and download file results
What does a result look like?
POI_results[0]
Let’s get the link to a granule (-1 to index the last granule in the results).
print(POI_results[-1].data_links()[0])https://data.asdc.earthdata.nasa.gov/asdc-prod-protected/TEMPO/TEMPO_NO2_L3_V03/2024.09.01/TEMPO_NO2_L3_V03_20240901T235825Z_S016.ncLet’s examine the file names present in the results object.
for r in POI_results:
granule_name = r.data_links()[0].split("/")[-1]
print(granule_name)TEMPO_NO2_L3_V03_20240831T235844Z_S016.nc
TEMPO_NO2_L3_V03_20240901T003849Z_S017.nc
TEMPO_NO2_L3_V03_20240901T105755Z_S001.nc
TEMPO_NO2_L3_V03_20240901T113800Z_S002.nc
TEMPO_NO2_L3_V03_20240901T121805Z_S003.nc
TEMPO_NO2_L3_V03_20240901T125810Z_S004.nc
TEMPO_NO2_L3_V03_20240901T133815Z_S005.nc
TEMPO_NO2_L3_V03_20240901T143815Z_S006.nc
TEMPO_NO2_L3_V03_20240901T153815Z_S007.nc
TEMPO_NO2_L3_V03_20240901T163815Z_S008.nc
TEMPO_NO2_L3_V03_20240901T173815Z_S009.nc
TEMPO_NO2_L3_V03_20240901T183815Z_S010.nc
TEMPO_NO2_L3_V03_20240901T193815Z_S011.nc
TEMPO_NO2_L3_V03_20240901T203815Z_S012.nc
TEMPO_NO2_L3_V03_20240901T213815Z_S013.nc
TEMPO_NO2_L3_V03_20240901T223815Z_S014.nc
TEMPO_NO2_L3_V03_20240901T231820Z_S015.nc
TEMPO_NO2_L3_V03_20240901T235825Z_S016.ncDownloading granules
Here we’ll download two of the files.
files = earthaccess.download(POI_results[8:10], local_path=".")5. Reading and inspecting the data
We first define a function for reading data from TEMPO_NO2_L3_V03 netCDF file.
def read_TEMPO_NO2_L3(fn):
with nc.Dataset(fn) as ds: # open read access to file
# Open the 'product' group.
prod = ds.groups["product"]
# Read variable vertical_column_stratosphere from the product group.
var = prod.variables["vertical_column_stratosphere"]
strat_NO2_column = var[:] # retrieve the numpy array.
fv_strat_NO2 = var.getncattr("_FillValue")
# Read variable 'vertical_column_troposphere' from the product group.
var = prod.variables["vertical_column_troposphere"]
trop_NO2_column = var[:]
fv_trop_NO2 = var.getncattr("_FillValue")
NO2_unit = var.getncattr("units")
# Read variable 'main_data_quality_flag' from the product group.
QF = prod.variables["main_data_quality_flag"][:]
# Read latitude and longitude variables, from the root (/) group, into a numpy array.
lat = ds.variables["latitude"][:]
lon = ds.variables["longitude"][:]
return lat, lon, strat_NO2_column, fv_strat_NO2, trop_NO2_column, fv_trop_NO2, NO2_unit, QFLet’s now examine the data in a granulue
granule_name = POI_results[8].data_links()[0].split("/")[-1]
print(granule_name)
lat, lon, strat_NO2_column, fv_strat_NO2, trop_NO2_column, fv_trop_NO2, NO2_unit, QF = (
read_TEMPO_NO2_L3(granule_name)
)TEMPO_NO2_L3_V03_20240901T153815Z_S007.ncprint("unit of NO2 column is ", NO2_unit) # unit of NO2 columnunit of NO2 column is molecules/cm^2# lat is a 1D array:
lat.shape(2950,)# lat is a 1D array:
lon.shape(7750,)# stratospheric NO2 column is a 3D array
# with second dimension being the number of latitudes and third being the number of longitudes:
strat_NO2_column.shape(1, 2950, 7750)# and so is tropospheric NO2 column:
trop_NO2_column.shape(1, 2950, 7750)Finding ‘good’ pixels
What is the fill value for the array of stratospheric NO2 column?
fv_strat_NO2np.float64(-1e+30)How many valid (non-fill) values are there?
len(strat_NO2_column[strat_NO2_column != fv_strat_NO2])22862500len(trop_NO2_column[trop_NO2_column != fv_trop_NO2])22862500How many pixels with high quality flag, 0, are there?
len(QF[QF == 0])7363629Notice that the number of non-fill values and high-quality values are different.
So, we need to create arrays of equal length to combine them to get total column.
good_data_mask = (QF == 0) & (trop_NO2_column != fv_trop_NO2) & (strat_NO2_column != fv_strat_NO2)
print(good_data_mask.shape)(1, 2950, 7750)How many good pixels are there?
good_trop_NO2_column = trop_NO2_column[good_data_mask]
len(good_trop_NO2_column)7363629Unfortunate reality - “good” pixels may contain negative column.
min(good_trop_NO2_column)np.float64(-5.4297665877187496e+16)Getting physically meaningful pixels
best_data_mask = good_data_mask & (trop_NO2_column > 0.0) & (strat_NO2_column > 0.0)best_trop_NO2_column = trop_NO2_column[best_data_mask]
len(best_trop_NO2_column)62625296. Working with the data to subset and plot
Spatial subsetting and masking out bad data
# Define a region of interest.
dlat = 5 # deg
dlon = 6 # deg
mask_lat = (lat > POI_lat - dlat) & (lat < POI_lat + dlat)
mask_lon = (lon > POI_lon - dlon) & (lon < POI_lon + dlon)
# Subset NO2 column arrays.
trop_NO2_column_loc = trop_NO2_column[0, mask_lat, :][:, mask_lon]
strat_NO2_column_loc = strat_NO2_column[0, mask_lat, :][:, mask_lon]
QF_loc = QF[0, mask_lat, :][:, mask_lon]
best_data_mask_loc = (QF_loc == 0) & (trop_NO2_column_loc > 0.0) & (strat_NO2_column_loc > 0.0)
# Create 2D arrays of latitudes and longitudes, by repeating lon/lat along rows/columns.
nlat, nlon = trop_NO2_column_loc.shape
lon_loc_2D = np.vstack([lon[mask_lon]] * nlat)
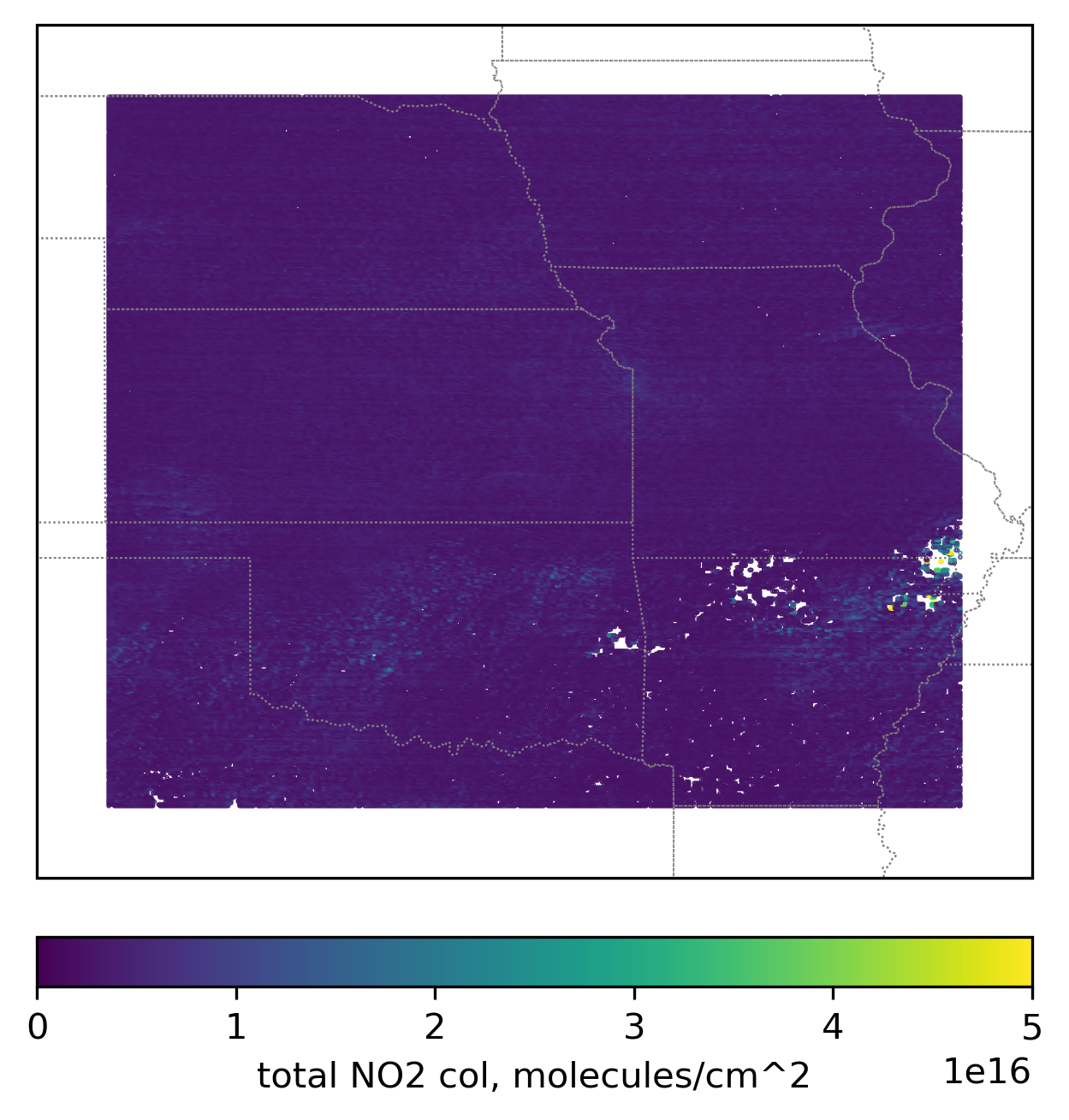
lat_loc_2D = np.column_stack([lat[mask_lat]] * nlon)Plotting spatial distribution
# Create a Cartopy projection
proj = ccrs.PlateCarree()
transform = ccrs.PlateCarree()
# Create a figure and axis.
fig, ax = plt.subplots(
1, 1, figsize=(5, 6), dpi=300, facecolor=None, subplot_kw={"projection": proj}
)
# Add coastlines and U.S. state borders
ax.coastlines(linewidth=0.5)
ax.add_feature(cfeature.STATES, linestyle=":", edgecolor="gray", linewidth=0.5)
im = ax.scatter(
lon_loc_2D[best_data_mask_loc],
lat_loc_2D[best_data_mask_loc],
s=0.1,
c=trop_NO2_column_loc[best_data_mask_loc] + strat_NO2_column_loc[best_data_mask_loc],
vmin=0,
vmax=5.0e16,
transform=transform,
)
ax.set_extent([-103, -89, 32, 44], crs=transform)
cb = plt.colorbar(
im,
ticks=[0, 1.0e16, 2.0e16, 3.0e16, 4.0e16, 5.0e16],
location="bottom",
fraction=0.05,
pad=0.05,
)
cb.set_label("total NO2 col, " + NO2_unit, fontsize=10)
plt.show()