Workflows Overview
Workflows are comprised of one or more AWS Lambda Functions and ECS Activities to discover, ingest, process, manage and archive data.
Provider data ingest and GIBS have a set of common needs in getting data from a source system and into the cloud where they can be distributed to end users. These common needs are:
- Data Discovery - Crawling, polling, or detecting changes from a variety of sources.
- Data Transformation - Taking data files in their original format and extracting and transforming them into another desired format such as visible browse images.
- Archival - Storage of the files in a location that's accessible to end users.
The high level view of the architecture and many of the individual steps are the same but the details of ingesting each type of collection differs. Different collection types and different providers have different needs. The individual boxes of a workflow are not only different. The branching, error handling, and multiplicity of the arrows connecting the boxes are also different. Some need visible images rendered from component data files from multiple collections. Some need to contact the CMR with updated metadata. Some will have different retry strategies to handle availability issues with source data systems.
AWS and other cloud vendors provide an ideal solution for parts of these problems but there needs to be a higher level solution to allow the composition of AWS components into a full featured solution. The Ingest Workflow Architecture is designed to meet the needs for Earth Science data ingest and transformation.
Goals
Flexibility and Composability
The steps to ingest and process data is different for each collection within a provider. Ingest should be as flexible as possible in the rearranging of steps and configuration.
We want to use lego-like individual steps that can be composed by an operator.
Individual steps should ...
- Be as ignorant as possible of the overall flow. They should not be aware of previous steps.
- Be runnable on their own.
- Define their input and output in simple data structures.
- Be domain agnostic.
- Not make assumptions of specifics of what goes into a granule for example.
Scalable
The ingest architecture needs to be scalable both to handle ingesting hundreds of millions of granules and interpret dozens of different workflows.
Data Provenance
- We should have traceability for how data was produced and where it comes from.
- Use immutable representations of data. Data once received is not overwritten. Data can be removed for cleanup.
- All software is versioned. We can trace transformation of data by tracking the immutable source data and the versioned software applied to it.
Operator Visibility and Control
- Operators should be able to see and understand everything that is happening in the system.
- It should be obvious why things are happening and straightforward to diagnose problems.
- We generally assume that the operators know best in terms of the limits on a providers infrastructure, how often things need to be done, and details of a collection. The architecture should defer to their decisions and knowledge while providing safety nets to prevent problems.
A Reconfigurable Workflow Architecture
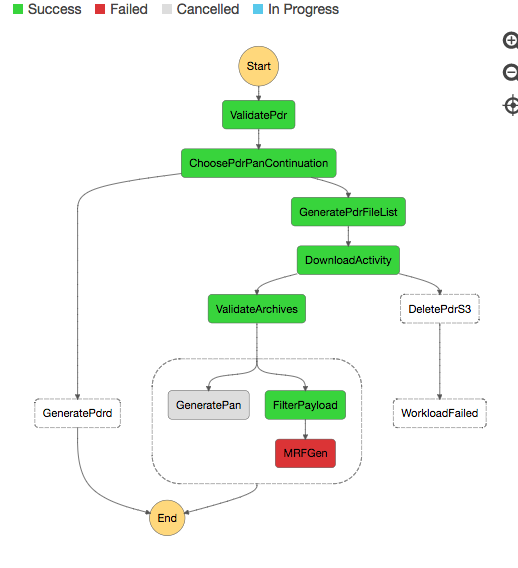
The Ingest Workflow Architecture is defined by two entity types, Workflows and Tasks. A Workflow is a set of composed Tasks to complete an objective such as ingesting a granule. Tasks are the individual steps of a Workflow that perform one job. The workflow is responsible for executing the right task based on the current state and response from the last task executed. Tasks are completely decoupled in that they don't call each other or even need to know about the presence of other tasks.
Workflows and tasks are configured as Terraform resources, which are triggered via configured rules within Cumulus.
See the Example GIBS Ingest Architecture showing how workflows and tasks are used to define the GIBS Ingest Architecture.
Workflows
A workflow is a provider-configured set of steps that describe the process to ingest data. Workflows are defined using AWS Step Functions.
Benefits of AWS Step Functions
AWS Step functions are described in detail in the AWS documentation but they provide several benefits which are applicable to AWS.
- Prebuilt solution
- Operations Visibility
- Visual diagram
- Every execution is recorded with both inputs and output for every step.
- Composability
- Allow composing AWS Lambdas and code running in other steps. Code can be run in EC2 to interface with it or even on premise if desired.
- Step functions allow specifying when steps run in parallel or choices between steps based on data from the previous step.
- Flexibility
- Step functions are designed to be easy to build new applications and reconfigure. We're exposing that flexibility directly to the provider.
- Reliability and Error Handling
- Step functions allow configuration of retries and adding handling of error conditions.
- Described via data
- This makes it easy to save the step function in configuration management solutions.
- We can build simple interfaces on top of the flexibility provided.
Workflow Scheduler
The scheduler is responsible for initiating a step function and passing in the relevant data for a collection. This is currently configured as an interval for each collection. The scheduler service creates the initial event by combining the collection configuration with the AWS execution context defined via the cumulus terraform module.
Tasks
A workflow is composed of tasks. Each task is responsible for performing a discrete step of the ingest process. These can be activities like:
- Crawling a provider website for new data.
- Uploading data from a provider to S3.
- Executing a process to transform data.
AWS Step Functions permit tasks to be code running anywhere, even on premise. We expect most tasks will be written as Lambda functions in order to take advantage of the easy deployment, scalability, and cost benefits provided by AWS Lambda.
- Leverages Existing Work
- The design leverages the existing work of Amazon by defining workflows using the AWS Step Function State Language. This is the language that was created for describing the state machines used in AWS Step Functions.
- Open for Extension
- Both
metaandtask_configwhich are used for configuring at the collection and task levels do not dictate the fields and structure of the configuration. Additional task specific JSON schemas can be used for extending the validation of individual steps.
- Both
- Data-centric Configuration
- The use of a single JSON configuration file allows this to be added to a workflow. We build additional support on top of the configuration file for simpler domain specific configuration or interactive GUIs.
For more details on Task Messages and Configuration, visit Cumulus configuration and message protocol documentation.
Ingest Deploy
To view deployment documentation, please see the Cumulus deployment documentation.
Tradeoffs, and Benefits
This section documents various tradeoffs and benefits of the Ingest Workflow Architecture.
Tradeoffs
Workflow execution is handled completely by AWS
This means we can't add our own code into the orchestration of the workflow. We can't add new features not supported by Step Functions. We can't do things like enforce that the responses from tasks always conform to a schema or extract the configuration for a task ahead of it's execution.
If we implemented our own orchestration we'd be able to add all of these. We save significant amounts of development effort and gain all the features of Step Functions for this trade off. One workaround is by providing a library of common task capabilities. These would optionally be available to tasks that can be implemented with Node.js and are able to include the library.
Workflow Configuration is specified in AWS Step Function States Language
The current design combines the states language defined by AWS with Ingest specific configuration. This means our representation has a tight coupling with their standard. If they make backwards incompatible changes in the future we will have to deal with existing projects written against that.
We avoid having to develop our own standard and code to process it. The design can support new features in AWS Step Functions without needing to update the Ingest library code changes. It is unlikely they will make a backwards incompatible change at this point. One mitigation for this is writing data transformations to a new format if that were to happen.
Collection Configuration Flexibility vs Complexity
The Collections Configuration File is very flexible but requires more knowledge of AWS step functions to configure. A person modifying this file directly would need to comfortable editing a JSON file and configuring AWS Step Functions state transitions which address AWS resources.
The configuration file itself is not necessarily meant to be edited by a human directly. Since we are developing a reconfigurable, composable architecture that specified entirely in data additional tools can be developed on top of it. The existing recipes.json files can be mapped to this format. Operational Tools like a GUI can be built that provide a usable interface for customizing workflows but it will take time to develop these tools.
Benefits
This section describes benefits of the Ingest Workflow Architecture.
Simplicity
The concepts of Workflows and Tasks are simple ones that should make sense to providers. Additionally, the implementation will only consist of a few components because the design leverages existing services and capabilities of AWS. The Ingest implementation will only consist of some reusable task code to make task implementation easier, Ingest deployment, and the Workflow Scheduler.
Composability
The design aims to satisfy the needs for ingest integrating different workflows for providers. It's flexible in terms of the ability to arrange tasks to meet the needs of a collection. Providers have developed and incorporated open source tools over the years. All of these are easily integrable into the workflows as tasks.
There is low coupling between task steps. Failures of one component don't bring the whole system down. Individual tasks can be deployed separately.
Scalability
AWS Step Functions scale up as needed and aren't limited by a set of number of servers. They also easily allow you to leverage the inherent scalability of serverless functions.
Monitoring and Auditing
- Every execution is captured.
- Every task run has captured input and outputs.
- CloudWatch Metrics can be used for monitoring many of the events with the StepFunctions. It can also generate alarms for the whole process.
- Visual report of the entire configuration.
- Errors and success states are highlighted visually in the flow.
Data Provenance
- Monitoring and auditing ensures we know the data that was given to a task.
- Workflows are versioned and the state machines stored in AWS Step Functions are immutable. Once created they cannot change.
- Versioning of data in S3 or using immutable records in S3 will mean we always know what data was created as the result of a step or fed into a step.
Appendix
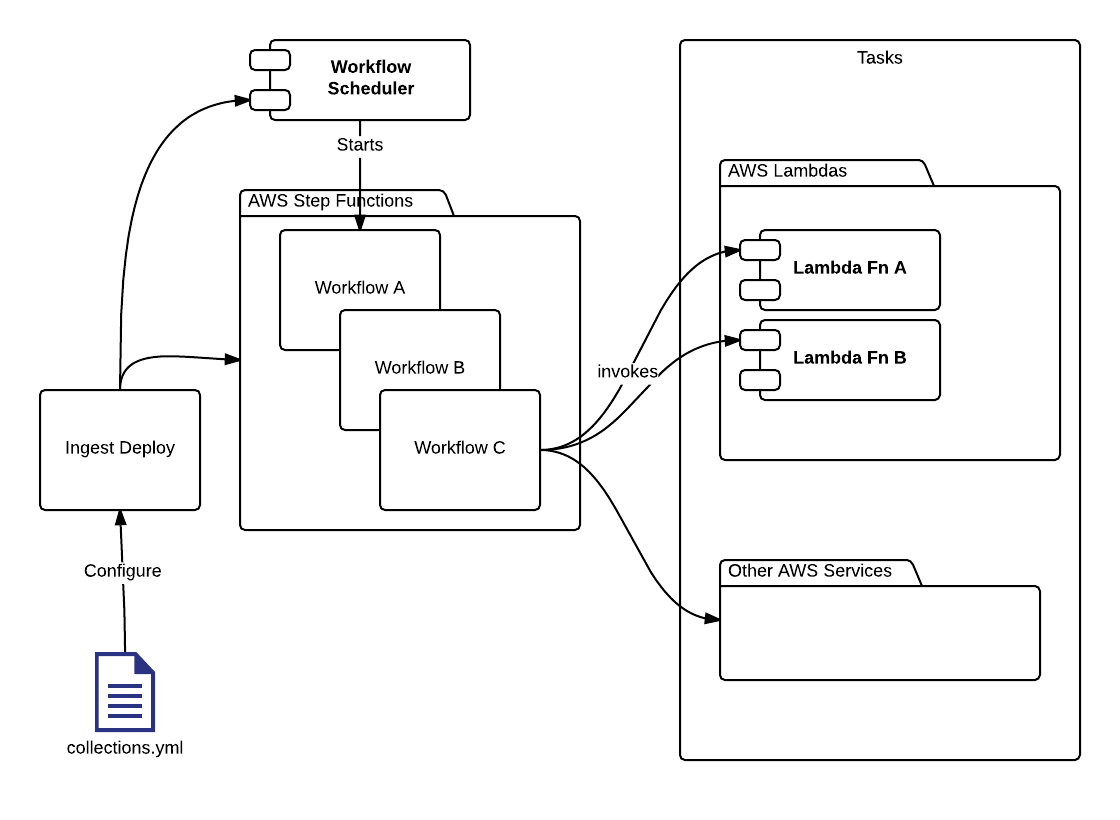
Example GIBS Ingest Architecture
This shows the GIBS Ingest Architecture as an example of the use of the Ingest Workflow Architecture.
- The GIBS Ingest Architecture consists of two workflows per collection type. There is one for discovery and one for ingest. The final stage of discovery triggers multiple ingest workflows for each MRF granule that needs to be generated.
- It demonstrates both lambdas as tasks and a container used for MRF generation.
GIBS Ingest Workflows
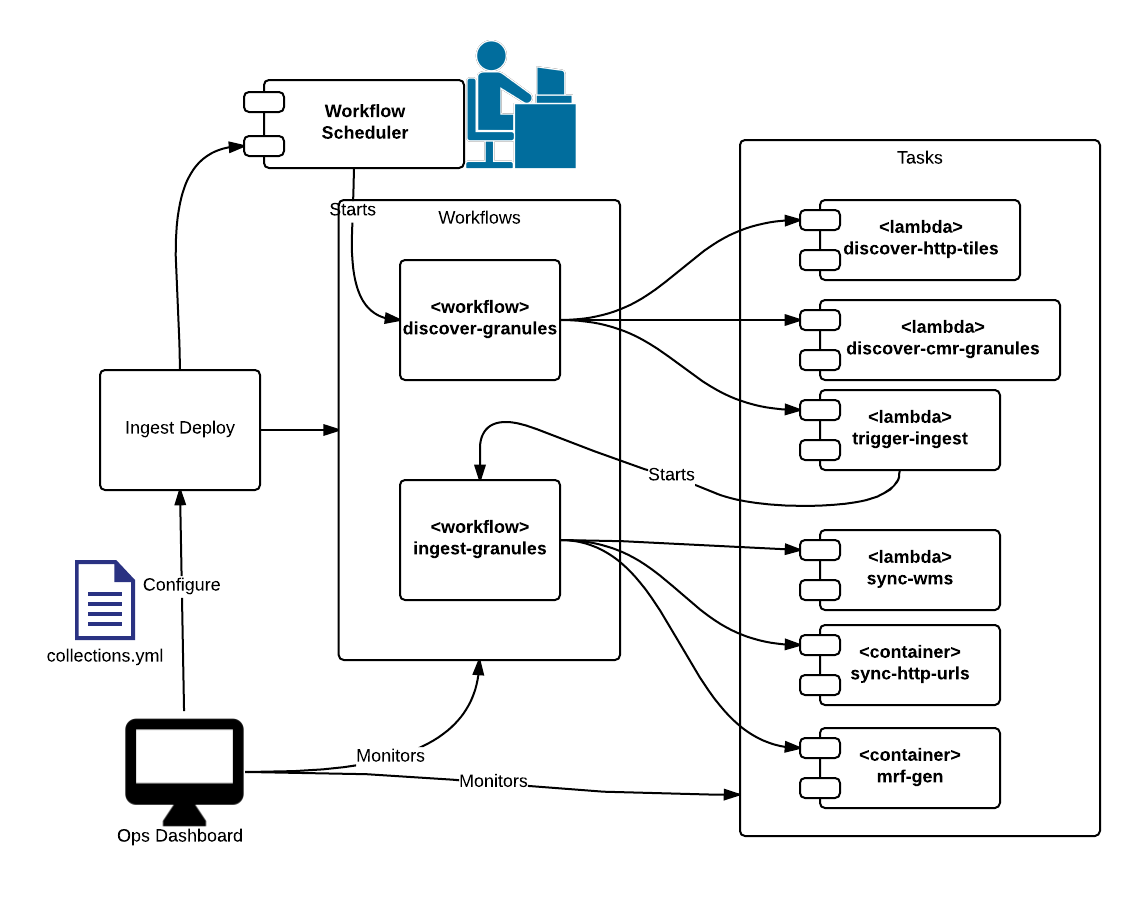
GIBS Ingest Granules Workflow
This shows a visualization of an execution of the ingets granules workflow in step functions. The steps highlighted in green are the ones that executed and completed successfully.