ORCA Reconciliation
As part of enhancing ORCA, a needed feature by the working group is being able to reconcile between the ORCA inventory and the Cumulus inventory to determine what file(s) are missing or extra in each catalog. The ORCA team has met with Cumulus several times to understand current reconciliation patterns. Notes from those interface meetings are available below. In addition, there are several resources available from Cumulus and LZARDS which also has to deal with reconciliation in a manor similar to ORCA. It is understood that ORCA will provide the data, but Cumulus will perform the comparison and reporting work to match current reconcile patterns.
- January 28, 2020 Meeting Notes
- March 4, 2021 Meeting Notes
- March 29, 2021 Meeting Notes
- LZARDS Prototype Reconciliation Reports
- Cumulus Reconciliation API
- Cumulus table definitions
Metadata Needed for Cumulus Comparison
The following filters can be applied to a query for determining which files to bring back for catalog comparison between the Cumulus inventory and ORCA.
| Name | Data Type | Description |
|---|---|---|
| providerId | List[str] | The unique ID of the provider(s) making the request. |
| collectionId | List[str] | The unique ID of collection(s) to compare. |
| granuleId | List[str] | The unique ID of granule(s) to compare. |
| startTimestamp | timestamp | Start time for cumulus_create_time date range to compare data. |
| endTimestamp | timestamp | End time for cumulus_create_time date range to compare data. |
When querying ORCA for the information these filters will be AND together for a comparison answer.
The sections below provide information on how these filters relate with the expected metadata objects, the attributes those data objects may need for comparison and investigation, and other items related to the data when making the comparison.
The metadata objects include the following.
- Provider (providerId)
- Collection (collectionId)
- Granule (granuleId, startTimestamp, endTimestamp)
- File - Needed for comparison.
- File Version - Needed for comparison, latest version only.
Relationship of the Metadata Objects
- A Provider contains an unique ID and is made up of one or more Collections.
- A Collection contains an unique ID that contains the short name, and version and is made up of one or more Granules.
- A Granule contains an unique ID and is made up of one or more Files.
- A File contains a name unique to the Granule ID and is made up of one or more File Versions.
- A File Version contains the versions, sizes, hashes and etags of a file along with pertinent dates.
Potential Attributes of the Metadata Objects
The following provides the potential metadata attributes that need to be captured for each object in order to properly filter and provide information back to Cumulus for reconciliation and Operator investigation of discrepancies. A draft schema for how the objects would interact and be tied together can be seen below.
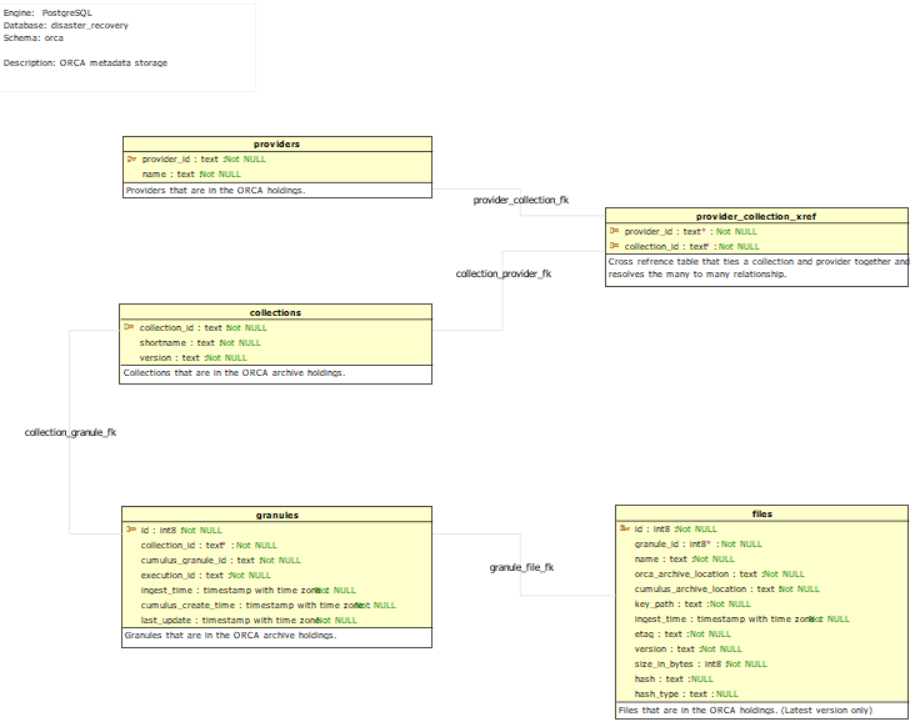
When noted, optional attributes are items not strictly needed for reconciliation but may provide value for additional enhancements which may occur in the future to query and filter the data for data management activities.
Provider Metadata Object
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| provider_id | string | providerId that is provided by Cumulus. | Must be unique. |
| name | string | Unique name of the provider. | Optional but may provide more value for future items. |
Collection Metadata Object
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| collection_id | string | collectionId that is provided by Cumulus. | Must be unique per providerId. |
| shortname | string | Short name of the collection (AST_L1A). | Optional but may provide more value for future items. |
| version | string | Version of the collection (061). | Optional but may provide more value for future items. |
I also considered adding attributes for collection configuration information like the excluded file types, default archive bucket, and other ORCA configurations. Thinking through it though, I felt it was better to leave these with Cumulus and perform a lookup if they are needed. This was primarily for two reasons. First, there are really no need for them for reconciliation within ORCA. Second, keeping the values in sync with changes made by operators through the Cumulus Dashboard seemed a bit challenging and did not appear to provide a real benefit.
Granule Metadata Object
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| id | string | Internal ORCA granule ID pseudo key. | None |
| collection_id | string | Collection ID from Cumulus that references the Collections table. | None |
| cumulus_create_time | timestamp | createdAt time from Cumulus | None |
| cumulus_granule_id | string | granuleId that is provided by Cumulus. | Must be unique per collectionId |
| execution_id | string | Step function execution ID from AWS. | Unique ID automatically generated by AWS |
| ingest_time | timestamp | Date and time in UTC that the data was originally ingested into ORCA. | None |
| last_update | timestamp | Date and time in UTC that information was updated. | None |
Note that the combination of the Cumulus Granule ID (cumulus_granule_id) and the Cumulus Collection ID (collection_id) is unique in the Cumulus granules table.
File Metadata Object
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| id | string | Internal ORCA file ID | None |
| granule_id | string | Granule that the file belongs to references the internal ORCA granule ID. | None |
| name | string | Name of the file. (MOD14A1.061.2020245.hdf) | Must be unique per granuleId |
| orca_archive_location | string | ORCA S3 Glacier bucket the file resides in. | None |
| cumulus_archive_location | string | Cumulus S3 bucket the file is expected to reside in. | None |
| key_path | string | S3 path to the file including the file name and extension, but not the bucket. | Must be unique per archive location |
| ingest_time | timestamp | Date and time in UTC that the data was originally ingested into ORCA | None |
| etag | string | etag of the file object in the AWS S3 Glacier bucket. | None |
| version | string | AWS provided version of the file. | Must be unique per file name/key_path |
| size_in_bytes | int | Size in bytes of the file. From Cumulus ingest. | Part of object passed to archive from Cumulus. |
| hash | string | Checksum hash of the file provided by Cumulus. | Optional. Part of object passed to archive from Cumulus. |
| hash_type | string | Hash type used to calculate the hash value of the file. | Optional. Part of object passed to archive from Cumulus. |
Note that in Cumulus the combination of the bucket (cumulus_archive_location) and key (key_path) is unique in the Cumulus files table.
File Version Object
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| version | string | AWS provided version of the file. | Must be unique per file name/key_path |
| is_latest | boolean | AWS provided flag denoting that it is the latest version. | Only one can be latest per file name/key_path. Depending of final table structure this may be optional. |
| etag | string | AWS provided etag of the versioned file. Semi unique | Potentially optional maybe able to be used for internal comparisons and/or data management investigations. |
| cumulus_etag | string | Cumulus provided AWS etag of the file in Cumulus. | Potentially optional. Would need to determine if this information passed along. May be helpful for data management comparisons. |
| size_in_bytes | bigint | Size in bytes of the file. From Cumulus ingest. | Part of object passed to archive from Cumulus. |
| hash | string | Checksum hash of the file provided by Cumulus. | Part of object passed to archive from Cumulus. |
| hash_type | string | Hash type used to calculate the hash value of the file. | Part of object passed to archive from Cumulus. |
| ingest_time | timestamp | Date and time in UTC that the file was ingested into ORCA | None |
It is possible that we may want to merge the File Version Object with the File Object. If we were to merge the two objects, here are some things to consider. By merging the objects we would likely only keep the latest version information of the file in the table. By doing this we do simplify reconciliation with Cumulus but, then the only catalog of all the versions available for a file would reside in the glacier S3 bucket. The implication of this is there is no other record of the various versions of the file. Also, we should need to query the S3 bucket if the data manager wanted to inquire what versions were available for a file in order to restore the proper version back or to identify versions that may be eligible for deletions based on policy. If we merge the objects, we may want to capture the total versions available for the file.
Return Metadata Needed by Cumulus
At a minimum, the following metadata should be returned back to Cumulus upon a successful query for reconciliation return from ORCA. The data below is what is needed for reconciliation comparison and general metadata that may be needed by the end user to perform analysis on discrepancies.
- Provider ID (providerId)
- Collection ID (collectionId)
- Shortname
- collection Version
- Granule ID (granuleId)
- Cumulus create time
- Execution ID
- Granule Ingest Date (ORCA) - may also be referred to as a Create Date.
- Granule Last Update (ORCA)
- File Name
- ORCA Location - archive bucket + archive path
- Cumulus Archive Location
- Key Path
- Etag
- File Size
- File Hash (Optional)
- File Hash Type (Optional)
- File Version (always send back latest version to compare)
A rough structure may look like the following below. In order to simplify comparisons, only the latest file version information will be returned. Enhancements we will need consider later include items like updating the latest flag in the database and glacier on a file version when doing a recovery.
{
"anotherPage": false,
"granules": [
{
"providerId": "lpdaac",
"collectionId": "MOD14A1___061",
"id": "MOD14A1.061.A23V45.2020235",
"createdAt": "2020-01-01T23:00:00Z",
"executionId": "u654-123-Yx679",
"ingestDate": "2020-01-01T23:00:00Z",
"lastUpdate": "2020-01-01T23:00:00Z",
"files": [
{
"name": "MOD14A1.061.A23V45.2020235.2020240145621.hdf",
"cumulusArchiveLocation": "cumulus-bucket",
"orcaArchiveLocation": "orca-archive",
"keyPath": "MOD14A1/061/032/MOD14A1.061.A23V45.2020235.2020240145621.hdf",
"sizeBytes": 100934568723,
"hash": "ACFH325128030192834127347",
"hashType": "SHA-256",
"version": "VXCDEG902"
},
...
]
},
...
]
}
Some items we will need to think about include managing paging (start/stop) for large returns and limiting size of the message across the wire. Additionally, results should be ordered by granule_id.
Potential ORCA Reconciliation Data Reporting Architecture
The following provides a rough, high level architecture for reporting the ORCA holdings to Cumulus. When providing data back to Cumulus, the solution should be able to handle the filters supplied and return back the needed data. In addition, the solution should be extensible and should allow for potential changes in the underlying data structure or storage engine as ORCA should be able to handle AWS PostgreSQL RDS, AWS Aurora PostgreSQL, and AWS Aurora PostgreSQL Serverless offerings.
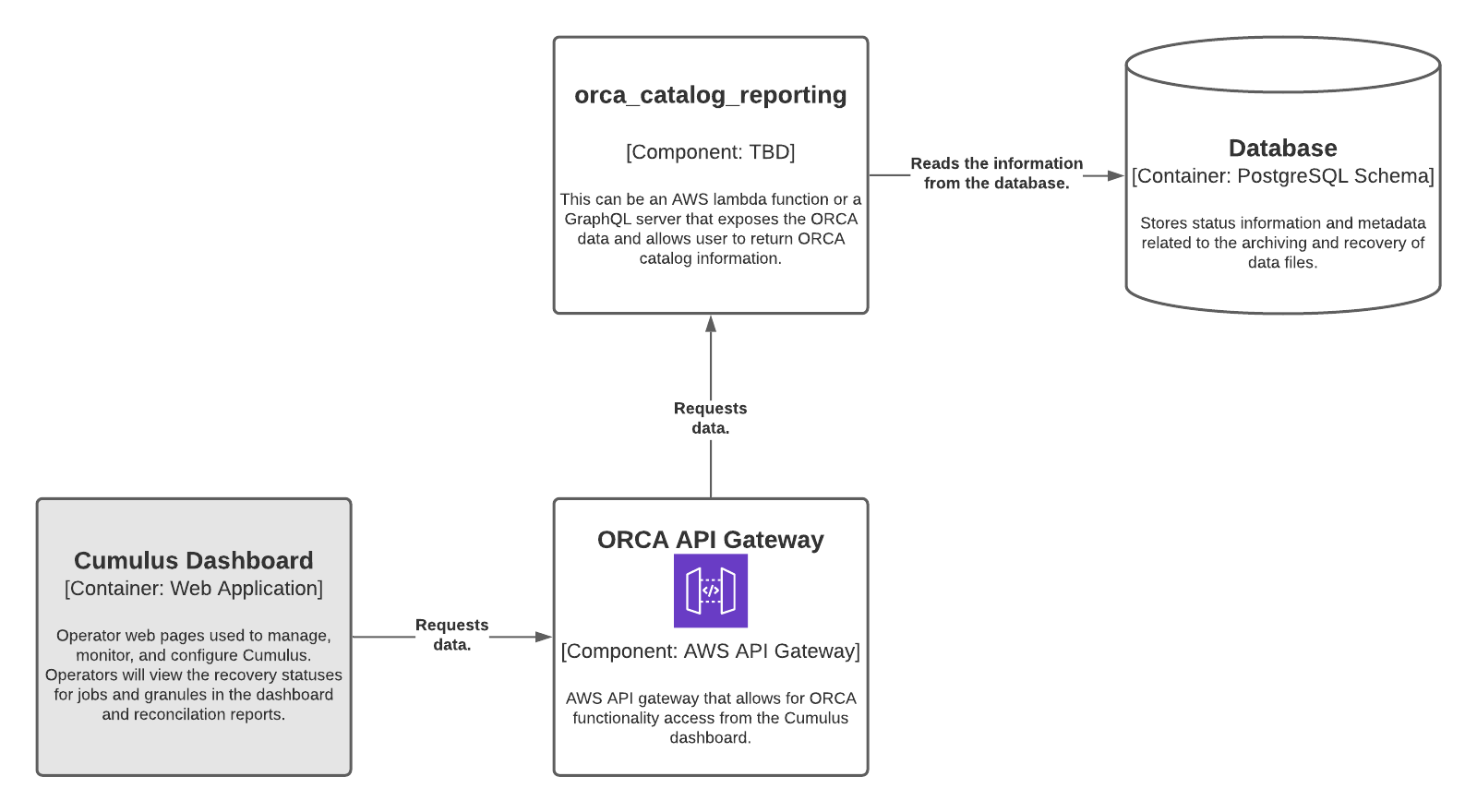
Populating the metadata
Populating the metadata objects with the proper metadata will need to come from various sources. The sections below will go through thoughts and ideas of where the metadata will originate from to populate the objects and potential ideas on what the underlying architecture may look like to perform the tasks.
Automated Cumulus Ingest Workflow
The conventional way of populating the objects with metadata would be through
the normal Cumulus ingest workflow that contains ORCA's copy_to_archive lambda.
The copy_to_archive lambda would need to be modified to take or pull additional
metadata needed to associate a granule's files to Cumulus, like providerId,
collectionId, granuleId, and various other file metadata information. The
additional collected metadata would sent to a queue to be written to the ORCA
catalog. The body sent to the queue would have enough information for another
ORCA lambda to write and/or update the records for the various objects in the ORCA
catalog.
Note that this new database write lambda or the copy_to_archive lambda may need
to make some additional queries to the S3 ORCA bucket to pull information like
version and other values. Looking at the original copy_to_archive, s3.copy
is used to copy data to the ORCA archive. Based on initial research located
here,
the s3.copy command does not return any information. See the test performed
below. Because of this, we will likely need to perform a listing on the object to
get additional information like the S3 object version as seen in the sample below.
Some items to consider when looking at the options for retrieving the additional
metadata include:
- speed - How fast can I get the needed metadata?
- cost - What is the cost impact of additional gets on the s3 bucket?
- complexity - Where is the best place to put these additional gets? Is the overall design and/or implementation to complex?
Boto3 Copy Test
import boto3
# Create the Client
s3_client = boto3.resource('s3')
# Get a source and destination to copy
copy_source = {"Bucket": "orca-sandbox-s3-provider", "Key": "MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065111.hdf"}
copy_destination = "orca-sandbox-archive"
# perform the copy command
copy_command = s3_client.meta.client.copy(copy_source, copy_destination, copy_source["Key"])
# Return results
print(copy_command)
None
Boto3 Get Additional File Information
This would occur after an s3.copy and assumes that the copy is synchronous and
that the file is not be ingested in parallel in a separate ingest pipeline that
would lead to a collision.
import boto3
# Create the Client
s3_client = boto3.resource('s3')
# Get a source and destination to copy
copy_source = {"Bucket": "orca-sandbox-s3-provider", "Key": "MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065111.hdf"}
copy_destination = "orca-sandbox-archive"
# Get the versioning information
file_versions = s3_client.meta.client.list_object_versions(Bucket=copy_destination, Prefix=copy_source["Key"] )
for version in file_versions["Versions"]:
if version["IsLatest"]:
print(version)
# Return results
{
'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"',
'Size': 6,
'StorageClass': 'STANDARD',
'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065111.hdf',
'VersionId': 'null',
'IsLatest': True,
'LastModified': datetime.datetime(2021, 5, 18, 16, 25, 58, tzinfo=tzutc()),
'Owner': {
'DisplayName': 'gsfc-esdis-edc-lpdaac-sandbox-7343-root',
'ID': '4d102362d8dc848404655e5418ff76cd342418b8d2ea3a04aa5db133bd6ac1db'
}
}
Note that the data we would likely want are ETag, VersionId, Size, and LastModified.
In the example above, the file I used was not part of a versioned S3 bucket thus
the null value for VersionId.
Boto3 Use Multipart Copy
In addition to the items above, I also looked at multipart copy which would return the information natively, but there is a 5Mb minimum size limit when using this functionality which is not small enough for some of the small files we may encounter. Reference information on multipart copy is provided below.
Manually Run ORCA Ingest Workflows
When manually running a workflow to ingest data into ORCA, it is assumed that the
same modified copy_to_archive lambda used in an automated workflow would be used
in the manual workflow. This would mean the translation lambda used to pass the
proper information from the Cumulus Dashboard call to the copy_to_archive lambda
would need to retrieve and provide information similar to the information that
is provided by the moveGranules lambda in the normal workflow. The translation
lambda will likely need to leverage Cumulus API calls to get information related
to the files and granule from Cumulus. The following cards that are planned to be
worked during PI 21.2 contain information related to this type of workflow and
translation lambda. See the list below.
- Understanding the Cumulus Dashboard Workflow Call Output
- Creating a Translate Lambda for Cumulus Dashboard Inputs for copy_to_archive
- Creating a Workflow for Ingesting Missing Files Into ORCA
Work related to reconciliation will likely require modifications to the translation lambda to pull additional information needed. The following are resources that may be utilized to gather additional granule and file information from Cumulus if needed. See the resource links below.
Note that the CMR call may not be necessary depending on the required metadata
needed. In addition, the CMR concept ID call can be retrieved from the cmrLink
key in the Cumulus API Get Granule Information. There may be some permission
issues to work through if the collection is not public or the granule is
hidden for some reason which means we would need to perform a login with a user
that would have access to see all of the providers holdings. Additional research
may need to be performed to better understand how to gather this information.
Back Population of the ORCA Catalog
Generally, the first two options listed will handle most use cases for adding information to the ORCA archive. However, for users that already have ORCA installations that are older than or equal to v3.x, a new workflow will need to be created to back populate the ORCA metadata catalog. Ideally, this workflow would be kicked off as part of the ORCA installation and/or migration.
As a general breakdown of the flow, the Lambda or Workflow will need to do the following:
- Query Cumulus looking for Collections configured for ORCA.
- Using the list of Collections configured for ORCA, retrieve the granule and file information.
- Get a list of the files in each ORCA bucket.
- Match attributes from the ORCA file list like file name, key path, and size to file(s) in the Cumulus list.
- Create a message body from the information similar to what
copy_to_granulewill perform. - Send the message body to the SQS FIFO queue so the database lambda can write the record to the database.
There are likely several ways to optimize this flow. The above is just a general concept to help get the information needed to match files. Collection regex information could also possibly be used. The Cumulus files table allows us to match key based on our listing, but the combination of key and Cumulus bucket are unique unique which means we could match multiple records based on key alone.
Note that this concept of back populating by matching data is not 100% accurate and is a best attempt to pull data and match it without "re-ingesting" items back into ORCA. This approach will likely need lots of logging and reporting to let end users know where discrepancies and best guesses or misses occur. We should also talk with end users about this option prior to implementing to determine if this is needed.
After discussions with the ORCA Working Group during the June meeting the concept above was discussed. The general consensus from the group was that re-population of ORCA through a standalone workflow similar to the items laid out in the manual run was the best option. In addition, the question of whether the back population method described above was a worthwhile path to pursue was posed on the orca Slack channel and the users currently using ORCA all agreed they would rather re-ingest into ORCA as seen by the Slack thread here.
Potential ORCA Catalog Population Architecture
The following is a potential architecture for populating the ORCA catalog under
normal use cases. Note that the SQS queue and orca_catalog_ingest lambda could
be replaced with a GraphQL server if deemed appropriate.
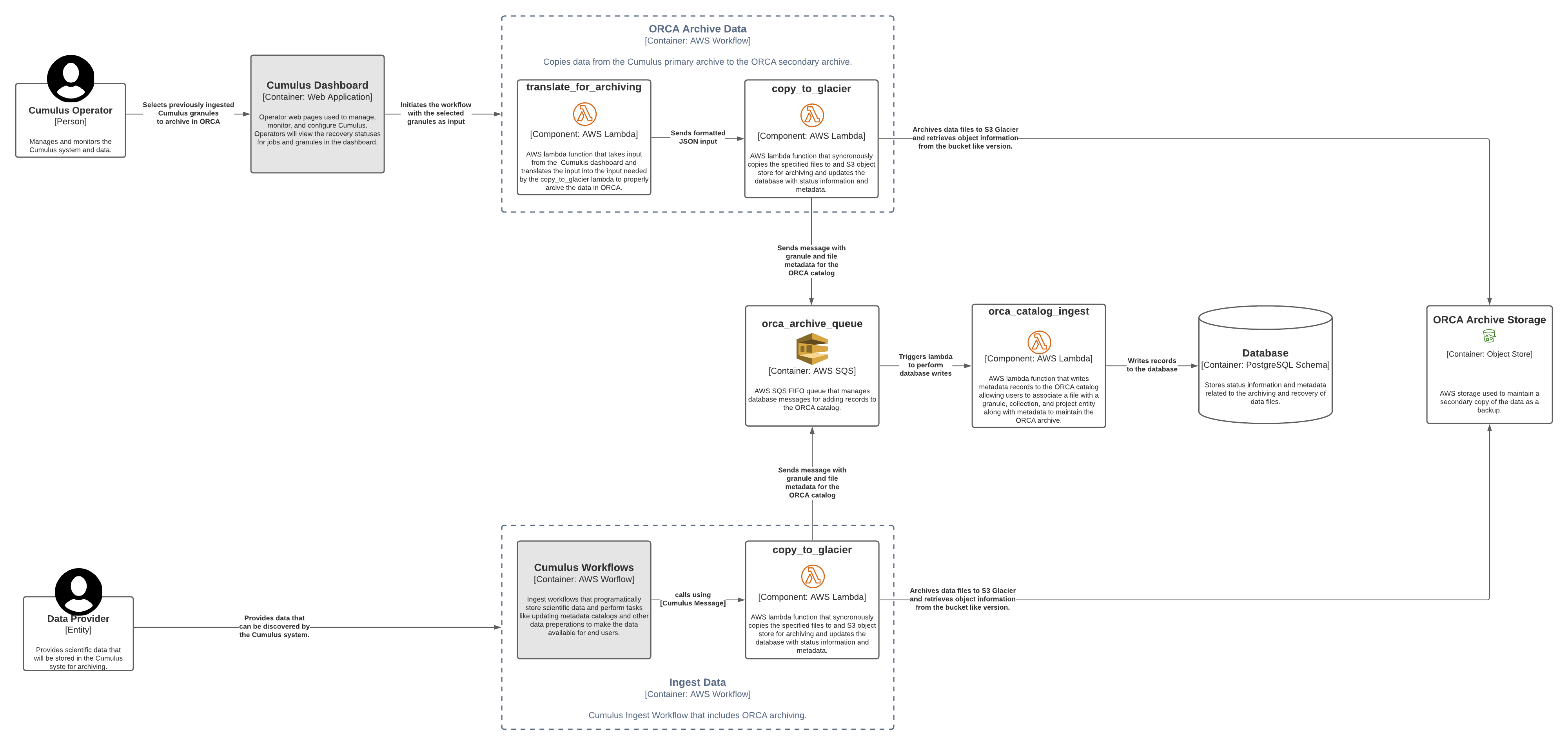
Possible Technologies for Enabling the Work
The following is a short list of technologies that could be leveraged during this work. These technologies fall within current architectures for Cumulus and extensions and may contribute to more rapid development of features as we progress. A full list of AWS services available in NGAP is available here.
API Gateway
The ORCA API Gateway provides an entry point for the Cumulus dashboard and users to interact directly with ORCA. For more information on the ORCA API gateway, see the API Gateway research page. All reconciliation calls from Cumulus should occur through the ORCA API Gateway.
GraphQL
GraphQL is a query language for APIs. This is an additional research spike topic. The promise of this route further consolidates our database read/write code while at the same time providing a single API endpoint for clients (both ORCA and Cumulus) to retrieve the data from ORCA. This technology though adding some complexity could simplify some code and design aspects.
Research aspects would include GraphQL server to use (COTS or home built). Impacts to AWS account (cost, speed, capabilities, security). Synergy with other projects like Cumulus.
Some initial resources to start would include the following:
- GraphQL Servers (prebuilt)
- Build your Own GraphQL Server
- GraphQL classes
- GraphQL Example with CMR
- Using Apollo Server as a Lambda
SQS
AWS SQS FIFO queues should be used to manage the records to be written to the ORCA database. This allows the team to decouple the database code from several lambdas and centralize the code to one area. This may or may not be needed if GraphQL is utilized.
AWS PostgreSQL RDS Offerings
To better align with Cumulus, ORCA will utilize the AWS PostgreSQL RDS offerings. See notes on the ORCA transition to the ORCA database here. The resultant code from the reconciliation work should be able to handle working with a PostgreSQL back end. Both PostgreSQL RDS and Amazon Aurora are viable back end choices that may be utilized. See a comparison article on the databases here.
NodeJS (Knex) / Python (SQLAlchemy)
An agnostic language framework for working with the database should be used some options include but are not limited to the items described below. Utilizing a more general API may help manage changes to the back end database engine with little or no code changes.
-
Nodejs and Knex is what the Cumulus team currently utilizes for database interactions. Implementation could follow best practices already established by the Cumulus team.
-
Python and SQLAlchemy Core is currently being used in some ORCA code.
Comparison between ORCA S3 and the ORCA Catalog
In addition to the comparison between the Cumulus catalog and ORCA, ORCA will also need to manage and maintain the catalog holdings between the ORCA database and the actual contents of the ORCA S3 buckets. This will require comparing the Key, LastModified, ETag, and Size keys to the of the files in the bucket to the ORCA holdings catalog. Discrepancies should be reported back to the user and detail orphan and missing files. We could possibly create a temporary reporting table to hold these values that the Cumulus Dashboard could display for us.
Some things to think through when designing this solution are factors of scale and managing them. To provide some thought and guidance, LP DAAC (one of the larger DAACs) has approximately 300 million files in the archive and growing. If all the files are also stored in ORCA, we will need to reconcile all the files in a smart and somewhat quick way on a semi regular basis.
Ideally, this reconciliation would occur on a regular schedule using a rule and reports would be stored in the database for users to retrieve the information. Additionally, the code should handle failures gracefully and be able to pick up where it left off either gathering the current contents in S3 or performing the ORCA catalog internal comparisons with S3.
Future enhancements may include displaying the information on the Cumulus dashboard, notifying operators via email or other means of discrepancies, or automated healing of the archive based on reconciliation results.
Getting a Listing from AWS S3
To get a file listing of an S3 bucket, the list_objects_v2 method can be used from the boto3 library. An example of the usage can be seen below. Some notable items if this library is used includes the following.
- Only a max of 1000 objects are returned per call. Additional logic will be needed to page through and get all of the results.
- The listing can be filtered by prefix. Possibly some room here to add configuration to look at the collection lever if a collection can be denoted by prefix.
- Version information is not included, only the latest file information is provided.
- An additional call will need to be made per object to look at versions available for a file.
- Only limited fields are returned from the call.
- Each list call does cost in AWS (tiny fractions of a cent).
Other considerations. It may be easier to load the data from the listing calls into a temporary table in the database and perform a handful of queries to find the delta information instead of looping through and doing a comparison in memory.
Example Using list_objects_v2
import boto3
# Set the variables
s3_client = boto3.resource('s3')
copy_destination = "orca-sandbox-archive"
# Get the listing
files = s3_client.meta.client.list_objects_v2(Bucket=copy_destination)
# Print the contents
for file in files["Contents"]:
print(file)
# Results
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065104.cmr.xml', 'LastModified': datetime.datetime(2020, 12, 15, 20, 4, 8, tzinfo=tzutc()), 'ETag': '"aaf96912124e107bf22016c7695fdcef"', 'Size': 2320, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065104.hdf', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 58, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065104.hdf.met', 'LastModified': datetime.datetime(2020, 12, 15, 20, 4, 7, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065104_ndvi.jpg', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 59, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065105.cmr.xml', 'LastModified': datetime.datetime(2020, 12, 17, 16, 35, 22, tzinfo=tzutc()), 'ETag': '"b4b1ea93026eece5390278d97bfd5c3e"', 'Size': 2320, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065105.hdf', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 58, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065105.hdf.met', 'LastModified': datetime.datetime(2020, 12, 17, 16, 35, 22, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065105_ndvi.jpg', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 58, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065106.cmr.xml', 'LastModified': datetime.datetime(2020, 12, 17, 17, 5, 43, tzinfo=tzutc()), 'ETag': '"67f535ab5d6398c2181ab7cf4763f84b"', 'Size': 2320, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065106.hdf', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 58, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065106.hdf.met', 'LastModified': datetime.datetime(2020, 12, 17, 17, 5, 42, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065106_ndvi.jpg', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 58, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065107.cmr.xml', 'LastModified': datetime.datetime(2020, 12, 17, 20, 58, 55, tzinfo=tzutc()), 'ETag': '"a71512f2cc5aa43edbf3573c76ccf5aa"', 'Size': 2320, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065107.hdf', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 58, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065107.hdf.met', 'LastModified': datetime.datetime(2020, 12, 17, 20, 58, 54, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065107_ndvi.jpg', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 59, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065108.cmr.xml', 'LastModified': datetime.datetime(2020, 12, 18, 19, 10, 16, tzinfo=tzutc()), 'ETag': '"6d76238799f45466a9431a9187aa5c70"', 'Size': 2320, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065108.hdf', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 58, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065108.hdf.met', 'LastModified': datetime.datetime(2020, 12, 18, 19, 10, 14, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065108_ndvi.jpg', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 59, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065109.cmr.xml', 'LastModified': datetime.datetime(2020, 12, 18, 19, 19, 21, tzinfo=tzutc()), 'ETag': '"f7ffec3ced795379e2346183221bd5e8"', 'Size': 2320, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065109.hdf', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 57, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065109.hdf.met', 'LastModified': datetime.datetime(2020, 12, 18, 19, 19, 20, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065109_ndvi.jpg', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 57, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065110.cmr.xml', 'LastModified': datetime.datetime(2020, 12, 18, 19, 28, 44, tzinfo=tzutc()), 'ETag': '"9fe1b5cf984cd64b8b7c31b49560ca6e"', 'Size': 2320, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065110.hdf', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 57, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065110.hdf.met', 'LastModified': datetime.datetime(2020, 12, 18, 19, 28, 44, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065110_ndvi.jpg', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 57, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065111.hdf', 'LastModified': datetime.datetime(2021, 5, 18, 16, 25, 58, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'STANDARD'}
{'Key': 'MOD09GQ/006/MOD09GQ.A2017025.h21v00.006.2017034065111_ndvi.jpg', 'LastModified': datetime.datetime(2021, 3, 23, 16, 59, 58, tzinfo=tzutc()), 'ETag': '"81f4b6c158d25f1fe916ea52e99d1700"', 'Size': 6, 'StorageClass': 'GLACIER'}
Potential Internal Reconciliation Architecture
The following provides an architecture of how ORCA internal reconciliation may work in an AWS environment with Cumulus. The architecture uses AWS' S3 Inventory report combined with S3 triggering to fire the comparison off on a normal schedule. Likely the running of this type of job will need to scale. When returning results through the API, it is recommended that we use a "path" parameter that filters based on the file's 'Key'. This will allow Cumulus to build values such as collection into a filter so long as they construct keys using it.
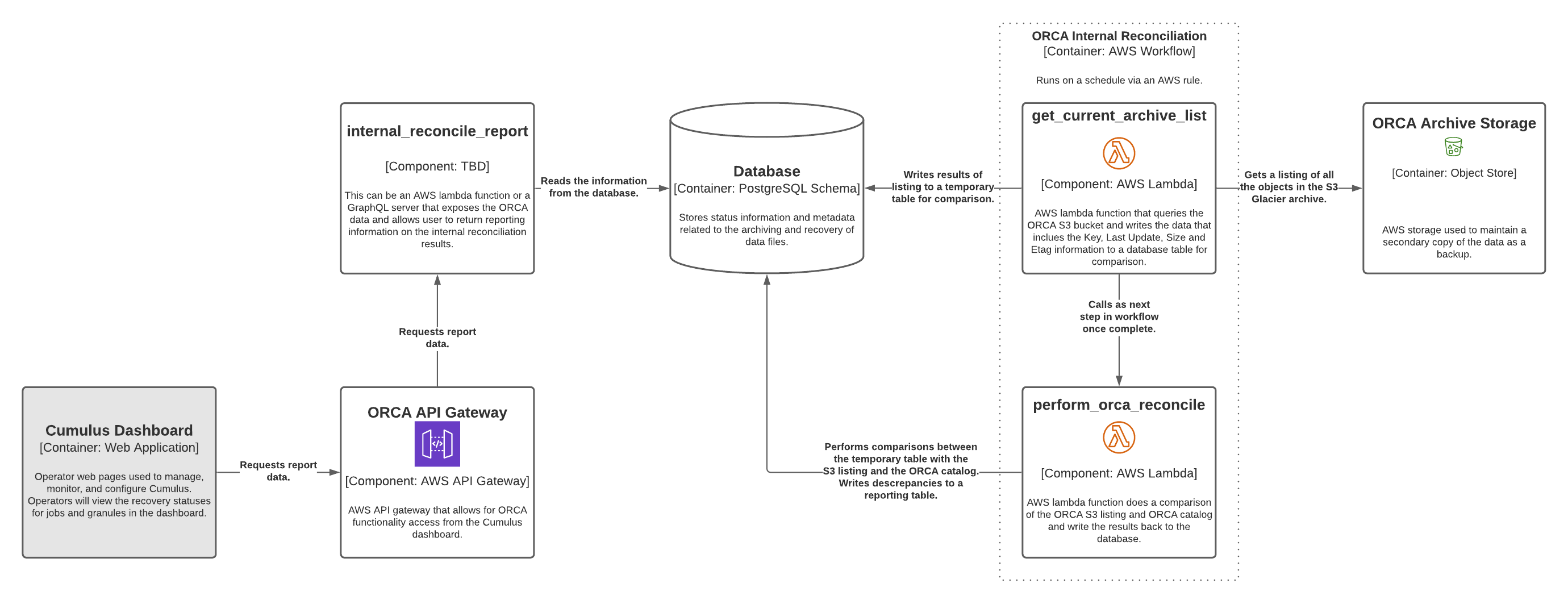
S3 Inventory Report
S3 Inventory reports are created on S3 buckets and post information about that bucket's contents to another bucket. For our purposes, the following options must be checked:
- Size
- Last modified
- Storage class
- ETag
Additionally, set Object versions to Include all versions.
Potential Internal Reporting Database Structure
The objects needed for managing ORCA internal reconciliation and reporting are provided in detail below.
An example schema showing how the objects interact and would be tied together is shown below.
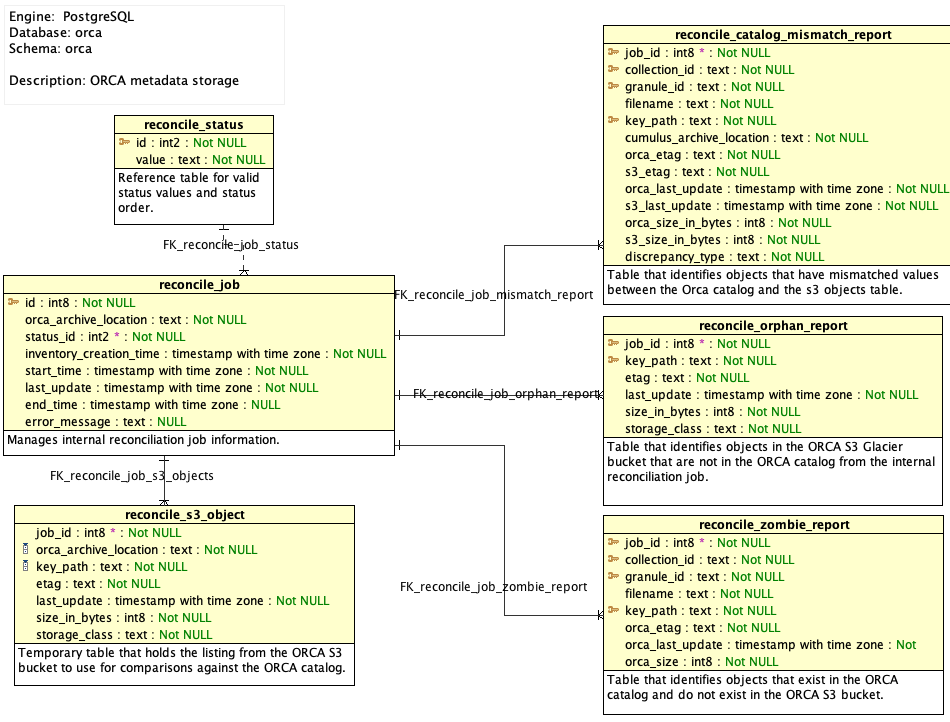
Status Table reconcile_status
Reference table for valid status values and status order.
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| id | int2 | Status ID. | Primary Key |
| value | string | Human readable status value. |
Internal Reconciliation Jobs Table reconcile_job
This table would capture internal reconciliation job information. Below is a sampling of attributes that may be needed. Based on design and implementation, additional attributes may be required. This table, in particular may need additional items for managing jobs.
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| id | int2 | Unique Job ID. | Primary Key |
| orca_archive_location | string | ORCA S3 Archive bucket the reconciliation targets. | Location in S3. |
| status_id | int8 | Current status of the job. | Generally reflect the stages of reconciliation. |
| inventory_creation_time | timestamptz | Inventory report initiation time from the s3 manifest. | Cannot be NULL |
| start_time | timestamptz | Start time of the job. | Cannot be NULL |
| last_update | timestamptz | Last time the status was updated. | Cannot be NULL |
| end_time | timestamptz | End time of the job. | NULLABLE column |
| error_message | string | Job error message in cases of failure. | NULLABLE column |
S3 Inventory Temporary Table reconcile_s3_object
This is a temporary object that would store the listing from the S3 bucket for comparison.
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| job_id | int8 | Reconcile job the listing is a part of. | Many to one relationship with the jobs table. |
| orca_archive_location | string | ORCA S3 Archive bucket the file resides in. | Location in S3. |
| key_path | string | Key key value from S3 listing. | Should be able to match to the key_path in the ORCA catalog File metadata object. Must be unique. |
| etag | string | ETag key value from S3 listing. | Should be able to match to the orca_etag value in the ORCA catalog File metadata object. |
| last_update | timestamptz | LastModified key value from the S3 listing. | Should be able to match the last_update value in the ORCA catalog File metadata object. |
| size_in_bytes | int8 | Size key value from the S3 listing. | Should be able to match the size value in the ORCA catalog File metadata object. |
| storage_class | string | StorageClass key value from the S3 listing. | May be used as a filter to exclude newly added items by excluding those with a value of STANDARD |
Internal Reconciliation Reporting Table Orphaned Files reconcile_orphan_report
This table would capture the files that reside in S3 but have no match in the ORCA catalog. Generally, these files would be deleted or investigated to see if items need to be re-ingested into ORCA. Note that entries with a last_update time after or immediately before the job's start_time may not have catalog entries yet due to a slight delay in the catalog population. This should be indicated when reporting results.
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| job_id | int8 | Reconcile job the report is a part of. | FK constraint back to the jobs table with a many to one relationship. |
| key_path | string | Key key value from S3 listing. | |
| etag | string | ETag key value from S3 listing. | |
| last_update | timestamptz | LastModified key value from the S3 listing. | |
| size_in_bytes | int8 | Size key value from the S3 listing. | |
| storage_class | string | StorageClass key value from the S3 listing. |
Internal Reconciliation Reporting Table S3 Missing reconcile_phantom_report
This table captures files that have records in the orca catalog, but are missing from S3. These files may have been deleted outside or a proper deletion flow, and may need to have their catalog entries manually cleared. Note that any entries with an orca_last_update after the job's start_time may show as an error due to race conditions with the catalog update process, and should be displayed as such when reporting results.
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| job_id | int8 | Reconcile job the report is a part of. | FK constraint back to the jobs table with a many to one relationship. |
| collection_id | string | Collection ID from the ORCA Collection object the file belongs to. | From Catalog. |
| granule_id | string | Granule ID from the ORCA Granule object the file belongs to. | From Catalog. |
| file_name | string | File name from the ORCA File object the file belongs to. | From Catalog. |
| key_path | string | Key path that includes the file name from the ORCA File object the file belongs to. | From Catalog. |
| orca_etag | string | Etag value from the ORCA File object the file belongs to. | From Catalog. |
| orca_last_update | timestamptz | Last Update value from the ORCA File object the file belongs to. | From Catalog. |
| orca_size | int8 | Size value from the ORCA File object the file belongs to. | From Catalog. |
Internal Reconciliation Reporting Table Catalog Missing or Mismatches reconcile_mismatch_report
This table would capture the discrepancies for reporting out to the operators about files that are missing from ORCA S3 or have different metadata values than what is expected. Note that any entries with an orca_last_update after the job's start_time may show as an error due to race conditions with the catalog update process, and should be displayed as such when reporting results.
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| job_id | int8 | Reconcile job the report is a part of. | FK constraint back to the jobs table with a many to one relationship. |
| collection_id | string | Collection ID from the ORCA Collection object the file belongs to. | From Catalog. |
| granule_id | string | Granule ID from the ORCA Granule object the file belongs to. | From Catalog. |
| file_name | string | File name from the ORCA File object the file belongs to. | From Catalog. |
| key_path | string | Key path that includes the file name from the ORCA File object the file belongs to. | From Catalog. |
| orca_etag | string | Etag value from the ORCA File object the file belongs to. | From Catalog. |
| s3_etag | string | ETag key value from S3 listing. | |
| orca_last_update | timestamptz | Last Update value from the ORCA File object the file belongs to. | From Catalog. |
| s3_last_update | timestamptz | LastModified key value from the S3 listing. | |
| orca_size_in_bytes | int8 | Size value from the ORCA File object the file belongs to. | From Catalog. |
| s3_size_in_bytes | int8 | Size key value from the S3 listing. | |
| discrepancy_type | string | Type of discrepancy encountered like "value x mismatch" |
Open Questions yet to be answered
- What is the proper date to use when receiving a date range from Cumulus for a reconciliation report?
- Should granule acquisition date be a part of the metadata?
- Should optional identified attributes be added an populated now or should we start with the minimum needed?
- Is GraphQL a good replacement for the current SQS - Lambda architecture?
Additional Artifacts from the Research
As part of the research, additional artifacts were created in order to help speed along prototyping and design. Information and instructions on the artifacts are provided below.
Aqua Data Studio ERD File
An entity relationship diagram (ERD) was created in Aqua Data Studio (ADS). The ERD provides table, constraint, and reference information for the various objects in the PostgreSQL database used by ORCA. The ERD diagram can be used for development and scripting as well as a way to visualize object interactions. The ADS ERD for ORCA can be downloaded here.
Schema Install SQL Scripts
In order to quickly prototype, two SQL install scripts were created. The scripts install the ORCA inventory catalog and the internal reconciliation tables respectively. The following preconditions are expected before the install scripts are run.
- The latest ORCA schema is installed in PostgreSQL (v3.x)
- The user is logged into the orca database as the admin user to run the script.
The ORCA inventory catalog build script is available for download here.
The ORCA internal reconciliation tables build script is available for download here.
Notes from ORCA schema refinement research
As part of the research, some refinements were made to the ORCA inventory catalog
schema. This includes refinements to the granules table and removal of the
provider_collection_xref table and the relationship between provider and
collection.
execution_idhas been added for helping with logging and tracing.cumulus_create_timehas been added for time based filtering with cumulus. The cumuluscreatedAttime will be a consistent time source between catalogsprovider_idhas been added to create a relationship between granule and provider.archive_locationhas been removed sinceorca_archive_locationalready exists in thefilestable.
Refined Granule Metadata Object
| Attribute Name | Data Type | Description | Notable Items |
|---|---|---|---|
| cumulus_granule_id | string | granuleId that is provided by Cumulus. | Must be unique per collectionId |
| provider_id | string | providerId that is provided by Cumulus | Ties a granule to a provider. |
| collection_id | string | collectionId that is provided by Cumulus | Ties a granule to a collection. The collectionId and granuleId combination must be unique. |
| execution_id | string | Step function execution ID from AWS. | Unique ID automatically generated by AWS |
| cumulus_create_time | timestamp | createdAt time provided by Cumulus when the granule was ingested. | This is the Cumulus archive time used for time based comparisons. |
| ingest_time | timestamp | Date and time in UTC that the data was originally ingested into ORCA | None |
| last_update | timestamp | Date and time in UTC that information was updated. | Potential time filter for Cumulus reconciliation. |
It is recommended to add tags for hash and hash_type when the values are available to files that get copied over to S3 bucket.
Refined ERD File & SQL script
The refined ADS ERD for ORCA can be downloaded here. The refined ORCA inventory catalog build script is available for download here.
Addressing open questions
- What is the proper date to use when receiving a date range from Cumulus for a reconciliation report?
- After discussion with the Cumulus team, we have decided to use
cumulus_create_timewhich is passed by CumuluscreatedAtkey in the CMA Message containing the timestamp that the granule began ingest of the granule into Cumulus. This timestamp will be used to filter results for Cumulus when asking for ORCA catalog inventory information and will be captured in the Cumulusgranulestable.
- After discussion with the Cumulus team, we have decided to use
- Should granule acquisition date be a part of the metadata?
- At this time, we are not going to include granule acquisition date since we cannot get it natively from Cumulus but might add it in the future.
- Should optional identified attributes be added and populated now or should we start with the minimum needed?
- Added step function's
execution_idto thegranulestable.
- Added step function's
- Is GraphQL a good replacement for the current SQS - Lambda architecture?
- Based on the research performed and prototype created on GraphQL, it is not currently a good replacement due to the lack of documentation which makes implementation difficult. Check GraphQL research notes for more information.