Research Notes on ORCA delete functionality.
Delete functionality use cases
Some use cases for delete functionality are as follows:
-
As a DAAC, I would like to remove data from ORCA that is invalid or expired in order to maintain a clean data archive. This can be achieved by a two-step process- an initial soft delete initiated by user, and a physical delete to permanently delete the data from S3 and database. It is assumed that the process is not automated and must be initiated by the user with an API call for both steps.
-
As a DAAC, I would like to remove data from ORCA only if it has been in archive for more than x days from initial ingest to keep from incurring additional cost for early removal.
This can be implemented by using soft delete. We can either flag the data in the database with a new column named
Pending Deletionor we can create a separate table that contains those data marked for deletion. Then after 90 days, we can permanently delete from the DB as well as the glacier bucket. If the data is stored in standard it would be 90 days but for deep archive, it would be 180 days. If the time the data stays in ORCA is less than the initial (90/180) days from ingest, any kind of delete operation will not be allowed. Some business logic should be added to the code to execute this rule. -
As a DAAC, I would like to configure the amount of time data remains in ORCA after being signaled to be deleted.
This should be configurable by each DAAC that is using ORCA. The number of days it would stay in ORCA would be based off of the soft delete date. Once the data stays in ORCA for greater than 90/180 days based on the glacier storage type used, that data would be eligible for a soft delete. The data would be eligible for a physical delete after the configured x days after the soft delete date. The data should stay in ORCA for x number of days for safety reasons. The configuration should be done using an environment variable during deployment. It is assumed that the configuration cannot be overridden except with a new deployment. Additionally, ORCA should prevent deletion of any kind from certain data like Level 0 or base data sets that are static. Some ways to implement this would be to have a configuration parameter we capture that says we are not able to delete from this collection or use an S3 bucket having bucket policies that prevents any deletes from happening.
-
As a DAAC, I would like only authorized personnel to be able to remove data from ORCA in a controlled way to minimize risk of accidental or malicious deletions.
This could be implemented with the use of NASA launchpad authentication since other teams such as Cumulus are already using this approach. This link is used to submit a new GSFC workflow request and most probably will be used to only allow specific users to perform the deletes. Contact
robert.a.meredith@nasa.govandtadd.buffington@nasa.govwith any issues regarding launchpad integration. The api gateway resource policy can be used to restrict certain users from accessing the api endpoint. For more information, see Controlling access to an API with API Gateway resource policies. Another technology to look into would be AWS Cognito which can be used to create customizable authentication and authorization solutions for the REST API. Amazon Cognito user pools are used to control who can invoke REST API methods. For more information, see Control access to a REST API using Amazon Cognito user pools as authorizer.
Authentication and authorization piece of this functionality needs further research to make sure only authorized users can perform deletes.
Currently AWS Cognito has some restrictions from use in production environments and should be avoided for now.
-
As a DAAC, I would like duplicate data to be versioned in ORCA in order to recover the proper version of the data based on the type of failure.
Versioning can be enabled at the bucket level by configuring the bucket properties via terraform or AWS console. After versioning is enabled in a bucket, it can never return to an unversioned state but can only be suspended on that bucket. Versioning can help recover objects from accidental deletion or overwrite. For example, if an object is deleted, Amazon S3 inserts a delete marker instead of removing the object permanently. The delete marker becomes the current object version. If the object is overwritten, it results in a new object version in the bucket. The previous version can always be restored. For more information, see Deleting object versions from a versioning-enabled bucket. The drawback of using versioning is the additional cost of storage for that versioned object. This can be solved by using object versioning with S3 Lifecycle policy. After a certain period of time defined, the versioned object will be marked as expired and automatically deleted from S3 bucket. This can be configured in bucket management via terraform. For more information, see S3 lifecycle policy
-
Perform a check with CMR and/or Cumulus to verify that the granule has been deleted from those locations prior to allowing the delete to proceed in ORCA.
This can be implemented in the existing lambda function that will be used to delete the data from ORCA. Before deleting from CMR and Cumulus, the UI should show a warning message to the user for additional confirmation. Additional items need to be discussed on this rule to determine when and how it would be implemented and to address corner cases like versioned file removal.
Initial ORCA Delete Functionality Architecture
The following is a potential architecture for ORCA delete functionality. Note that this could possibly change after discussing open questions with other teams.
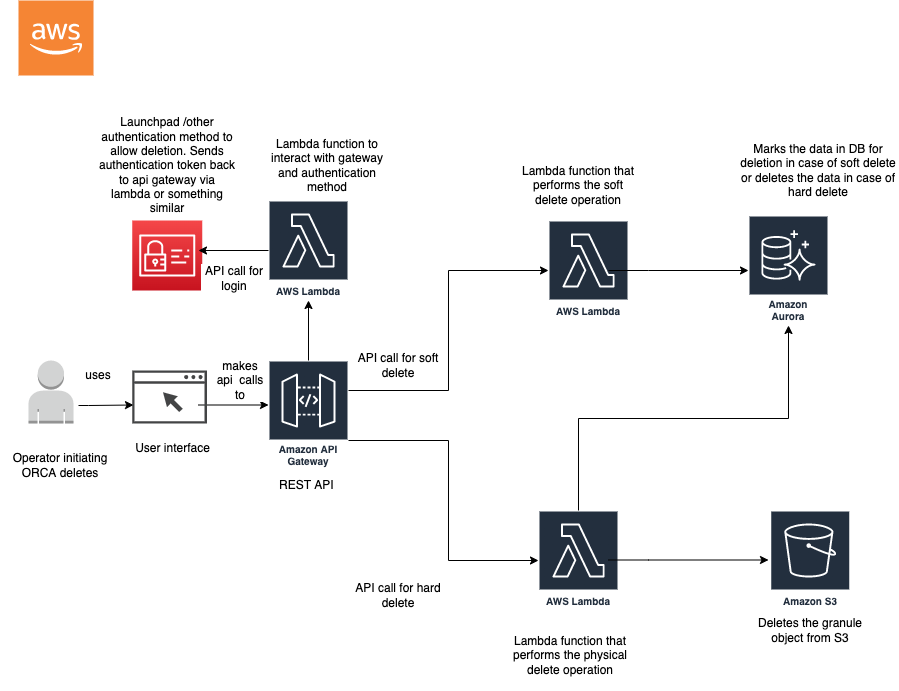
User Interface
The user interface is used to show warning messages to end user while performing the deletes. The UI should be able to interact with Cumulus dashboard and other apps as needed. It also makes api calls to the API gateway for delete operations.
API gateway
API gateway is currently used by end users for creating reconciliation reports and getting status update of recovery granules and jobs. This can be used for creating API calls made by end users for deletion.
The API gateway should act as a trigger to the lambda functions that actually perform the deletion in the backend. In addition, it should also trigger a login lambda function that gets the authentication token from Launchpad possibly for user login and verification.
An API gateway with two different resources need to be created- one for the soft delete API call and one for the hard delete API call. In order to deploy this via terraform, a private rest api with two resources need to be created. In case of using private API, the vpc endpoint ID for the gateway will be required.
The REST API should use a POST http method and the integration type should be AWS.
If lambda function is used with the API, a lambda permission resource should be created in terraform giving access to lambda:InvokeFunction action so that the API can trigger the lambda. In addition, the api gateway resource policy can be used to restrict certain IP addresses and VPC if needed from accessing the API endpoint. Check API gateway examples currently used by ORCA.
Lambda function
The delete functionality can be performed by two lambda functions based on initial research. One of the lambda functions will be used to perform soft delete- only flag the granule in the database for deletion after 90 days in case of standard glacier or 180 days in case of deep glacier. The lambda should also verify with CMR and/or Cumulus that the granule has been deleted from those locations prior to allowing the delete to proceed in ORCA. The lambda will be triggered by an API call made by the user once the user is authenticated with Launchpad.
The other lambda function can be used to perform a physical delete from S3 archive as well as from the database. The lambda code should addresses the rule that the data cannot be physically deleted until the DAAC configured x number of days. This will require further discussions with ORCA team and ORCA Working group before performing the actual work.
Deleting objects from AWS S3
To delete an object from an S3 bucket, the delete_objects can be used from the boto3 library. An example of the usage can be seen below. Some notable items if this library is used includes the following.
- It can be used to delete up to 1000 objects from a bucket using a single API call.
- When performing this action on an MFA Delete enabled bucket that attempts to delete any versioned objects, an MFA token must be included or else it will fail.
- If the object specified in the request is not found, Amazon S3 returns the result as deleted.
- Each DeleteObjects API incurs a little cost of $0.05/10000 requests.
Example Using delete_objects
import boto3
s3_client = boto3.client('s3')
bucket = "riz-orca"
response = s3_client.delete_objects(
Bucket=bucket,
Delete={
'Objects': [
{
'Key': 'MOD09A1.006/MOD09A1.A2019025.h07v03.006.2019037205734.hdf',
}
]
}
)
print(response)
# Results
{
"ResponseMetadata":{
"RequestId":"KJCZAPM0RWMJNNC7",
"HostId":"z2fRlgMxT10ApzcyDOLp3REn3PjM71OSgdH0oPpe4v2pHchmSTPCfEjBjTx00PyTL55wgmQ7gF4=",
"HTTPStatusCode":200,
"HTTPHeaders":{
"x-amz-id-2":"z2fRlgMxT10ApzcyDOLp3REn3PjM71OSgdH0oPpe4v2pHchmSTPCfEjBjTx00PyTL55wgmQ7gF4=",
"x-amz-request-id":"KJCZAPM0RWMJNNC7",
"date":"Tue, 08 Mar 2022 05:19:07 GMT",
"content-type":"application/xml",
"transfer-encoding":"chunked",
"server":"AmazonS3",
"connection":"close"
},
"RetryAttempts":0
},
"Deleted":[
{
"Key":"MOD09A1.006/MOD09A1.A2019025.h07v03.006.2019037205734.hdf"
}
]
}
Logging for Auditing
Additional logging should be collected during the deletion process to keep records for safety and security purposes. Some logging to capture might include who deleted the data, when how many granules were deleted over a particular timespan, from which collections was it deleted, and what workflow was used to delete them.
Cloudwatch logs and cloudtrail can be used to collect logging information. In addition, S3 server access logging can be used at the bucket level which would provide detailed records for the requests that are made to a bucket. The log information can be useful in security and access audits. AWS will collect access log records, add the records in log files, and then upload log files to the target bucket as log objects. There is no extra charge for using the service except the cost for storing the log files in S3.
Open Questions answered after meeting with ORCA users on 02/14/2024
- Regarding user authentication and authorization for deletes, do we have to pass any temporary tokens? How will this integrate with Cumulus calls to our API? Do we utilize an authentication token from API gateway?
- Cumulus team mentioned they have used AWS Cognito for something similar. Need to check with NGAP if this service is approved for used.
- Check with NGAP/Matt Martens about the use of Launchpad/soft tokens for user authentication and delete authorization.
- Since
deleteObjectsboto3 API call is limited to 1000 deletes per call, can we batch this up? Are there better ways to do batch deletes? What are the rules this has to follow?- GES DISC used batch operation but not sure if it can be used for delete operation. More research/testing needed.
- LP Cumulus suggested to investigate running deletes through parallelism/ lambda fan in fan out for better performance.
- What information should we capture from the delete logs? Do we delete the records, move them to an audit table or store them in S3 like in server access logging? How long do we keep them?
- DAACs want to use their own retention period for logging. ORCA will create an optional variable for log retention period.
- GES DISC suggested to use default cloudwatch logs similar to ingest. S3 storage will incur additional cost.
- How do we handle situations like deleting a version of a granule and not the complete granule?
- No suggestions yet. Need additional discussion.
- When removing versioned data granule, do we remove all the versions or do we remove all but the last and keep the delete marked version for longer?
- No suggestions yet. Need additional discussion.
Future directions
Few cards have been created to perform the ORCA delete functionality work based on initial research. It can be assumed that some of these cards will get modified once we have more discussion with other teams. This should be revisited during PI planning/team meetings to confirm the use cases/requirements before starting the work. Some of the cards created to finish the task include:
- https://bugs.earthdata.nasa.gov/browse/ORCA-394- Create Lambda function for performing soft deletes from ORCA
- https://bugs.earthdata.nasa.gov/browse/ORCA-395- Create Lambda function for performing physical/hard deletes from ORCA
- https://bugs.earthdata.nasa.gov/browse/ORCA-396- Create API gateway resource for performing ORCA delete functionality
- https://bugs.earthdata.nasa.gov/browse/ORCA-397- Integrate ORCA delete API gateways with Launchpad and add users who can perform the deletion.
- https://bugs.earthdata.nasa.gov/browse/ORCA-398- Investigate logging for ORCA delete functionality.
- https://bugs.earthdata.nasa.gov/browse/ORCA-402- Discuss the open questions regarding the delete functionality with the larger team (Cumulus IX,OX/GHRC).
References
- https://wiki.earthdata.nasa.gov/display/CUMULUS/ORCA+Data+Management+Use+Cases
- https://wiki.earthdata.nasa.gov/display/CUMULUS/ORCA+Prevention+Use+Cases
- https://wiki.earthdata.nasa.gov/display/CUMULUS/2022-03-02+ORCA+Meeting+notes
- https://docs.aws.amazon.com/AmazonS3/latest/userguide/ServerLogs.html
- https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html#S3.Client.delete_objects
- https://docs.aws.amazon.com/apigateway/latest/developerguide/apigateway-control-access-to-api.html
- https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-lifecycle-mgmt.html
- https://www.sumologic.com/insight/s3-cost-optimization/
- https://aws.amazon.com/premiumsupport/knowledge-center/s3-undelete-configuration/