Development Guide
Why fmdtools?
Use fmdtools to improve your understanding of the dynamics of hazardous behavior. The fmdtools library was developed to study resilience, which is an important consideration in designing safe, low-risk systems. Resilience is the ability of a system to mitigate hazardous scenarios as they arise. As shown below, the key defining aspect of resilience is the dynamics of failure events, which may lead to recovery (or, a safe outcome) or failure (or, an unsafe outcome).
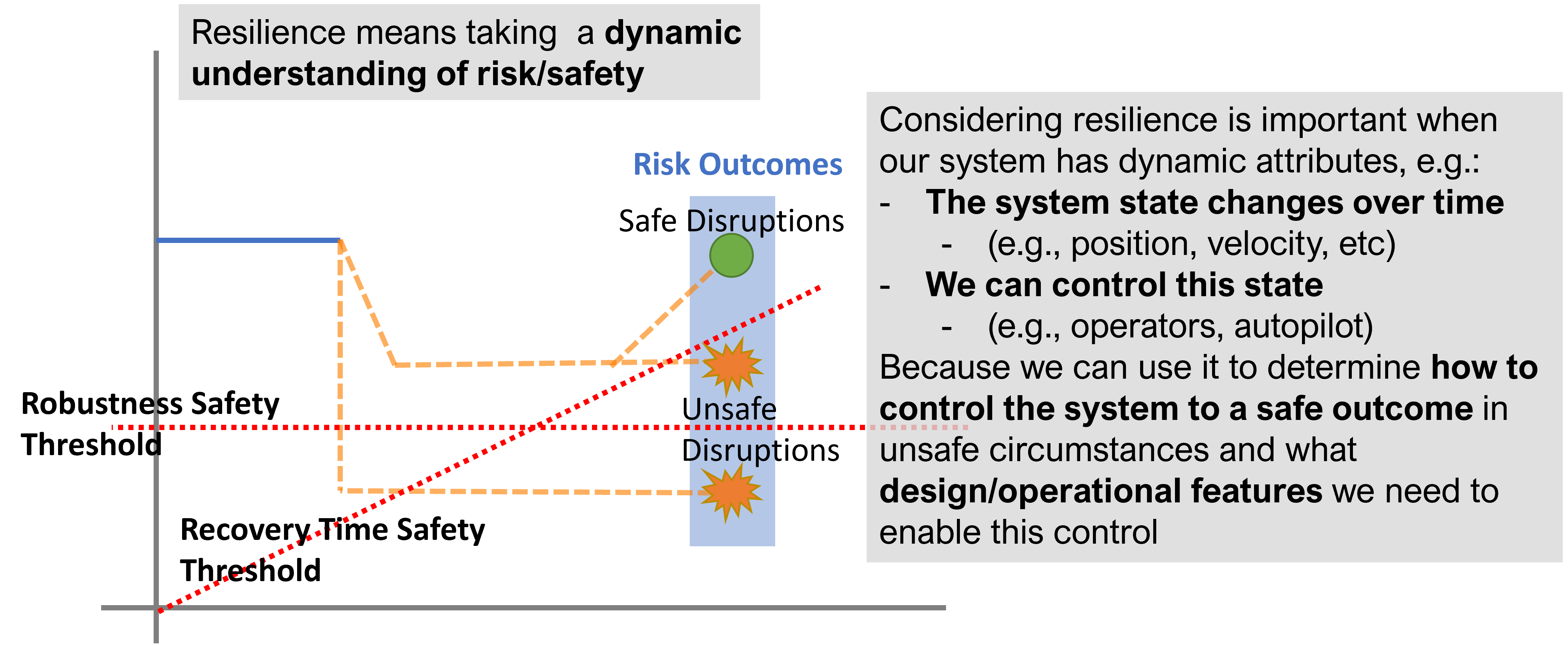
Resilience is important to consider when dynamics of system behavior can lead to hazardous or unsafe outcomes.
The impetus for developing fmdtools was a lack of existing open-source tools to model these dynamics at a high level (i.e., functions and flows) in the design process. Thus, researchers in this area had to re-implement modeling, simulation, and analysis approaches for each new case study or methodological improvement. The fmdtools package resolved this problem by separating resilience modeling, simulation, and analysis constructs from the model under study, enabling reuse of methodologies between case studies. The goals of the fmdtools project have since shifted to the more general goal of improving the hazard assessment process by better representing systems resilience. Towards this end, fmdtools provides the following capabilities:
Representing system dynamics to enable the quantification of resilience properties. Typically, hazard assessment processes neglect the consideration of resilience because they focus on the immediate effects of faults on the function of the system, rather than an assessment of how these effects play out over time. The fmdtools library enables this consideration by providing a behavioral view of hazardous scenarios. This is important both for understanding hazardous behaviors, but also how they can be mitigated as they arise.
Representing operational behaviors and actions to enable the assessment the contributions of human operators and autonomous/AI-enabled systems to overall risk and resilience. Traditional hazard assessment approaches do not consider the feedback between operators, the system, and the environment, instead leaving them as “accidents” or “mistakes” to be blamed on the operator. With fmdtools, these hazards can be considered directly by modelling potential operator behaviors and how they support or degrade overall systems resilience. These approaches can also be used to better understand the risks posed by AI/autonomous systems.
Enabling a Model/Simulation-based hazard analysis paradigm by allowing the iterative, consistent analysis of resilience through the design, implementation, and V&V processes. The traditional hazard assessment process is a manual, expert-driven approach that is inefficient to iterate on or change as a the design changes or assumptions are validated (or invalidated). In contrast, because all assumptions in fmdtools are represented as code, they can easily be modified as assumptions change while maintaining the overall integrity of the analysis. Furthermore, simulations in fmdtools can be efficiently and consistently be varied to analyze a system in more detail or in different configurations.
While this libary primarily provides code structures, a major objective of this library is further to enable these techniques to be used in a graphical simulation tool for hazard assessment.
Introductory Tutorial
The best place to start to getting acquanted with basic syntax and functionality is the Intro to fmdtools workshop (download slides as pdf), which uses the Pump example to introduce the overall structure and use of fmdtools. Other models are further helpful to demonstrate the full variety of methods/approaches supported in fmdtools and their applcation for more advanced use-cases.
Glossary
You can use the glossary as a reference to understand basic simulation and analysis concepts in fmdtools.
- Function
A piece of functionality in a system which has its own defined behavior, modes, and flow connections, and may be further instantiated by a component architecture or action sequence graph. In general, functions are the main building block of a model defining how the different pieces of the system behave. Functions in fmdtools are specified by extending the
fmdtools.define.block.function.Functionclass.- Flow
A data structure which connects functions–traditionally energy, material, or signal. Defined using the
fmdtools.define.flow.base.Flowclass.- Role
A defined attribute of an fmdtools class which refers to a user-defined (or default) subclass of a corresponding fmdtools data structure. For example, Blocks have the container Block.s (for state) which may be filled by a subclass of
fmdtools.define.container.state.State.- Internal Flow
A flow object that is internal to a
fmdtools.define.block.function.Functionwhich is not present in the overall model definition.- Model
A simulation that defines system behavior. Models contain functions and flows, their graph connections, parameters related to the simulation configuration, as well as methods for classifying simulations.
- Behavior
How the states of a system unfold over time, including in the various mode s it may encounter. Defined in Function s, Component s, and Action s using
fmdtools.define.Block.behavior(),fmdtools.define.Block.static_behavior(),fmdtools.define.Block.dynamic_behavior(), andfmdtools.define.Block.condfaults()- Graph
A view of simulation construct connections and/or relationships embodied by the
fmdtools.analyze.graph.Graphclass and sub-classes (which uses networkx to represent the structure itself).- Component
A physical component that embodies specific behavior for a function. May have mode s and behavior s of its own. Specified by extending the
fmdtools.define.block.component.Componentclass.- Component Architecture
The physical embodiment of a function that encompasses multiple Component s. Represented via the
fmdtools.define.architecture.component.ComponentArchitectureclass.- Mode
Discrete modifications of a behavior specified as entries in the
fmdtools.define.container.mode.Mode()class. Often used to control if/else statements in a behavior method within a function.- Fault Mode
Undesired mode, which leads to hazardous behavior. For example, a lamp may have “burn-out” due to a “flicker” mode.
- Operational Mode
Defined mode that the system progresses through as a part of its desired functioning. For example, a light switch may be in “on” and “off” modes.
- Action Sequence Graph
An instance of the
fmdtools.define.architecture.action.ActionArchitecturewhich embodies a (human or autonomous) agent’s sequence of tasks which it performs to accomplish a certain function.- Agent
An actor which controls behaviors in a system. May be modeled as a function.
- Environment
The uncontrolled aspect of a system which may effect system inputs and behaviors. May be modeled as a function.
- Action
A specific task to be performed by an agent used to represent human/autonomous operations. May be specified by extending the
fmdtools.define.block.action.Actionclass and added to afmdtools.define.block.function.Functionas a part of an Action Sequence Graphfmdtools.define.architecture.action.ActionArchitecture.- Rate
The expected occurence (frequency) of a given mode, which may be specified in a number of ways using
fmdtools.define.container.mode.Mode.faultmodes().- Cost
A metric used to define severity of a scenario. While cost is defined in a monetary sense, it should often be defined holistically to account for indirect costs and externalities (e.g., safety, disruption, etc). One of the default outputs from
fmdtools.define.block.base.Simulabl.find_classification()for models or blocks.- Expected Cost
A metric used to define risk of a scenario, calculated my multiplying the rate and cost.
- Endclass
The end-state classification given from
fmdtools.define.block.base.Simulabl.find_classification().- Scenario
A specific set of inputs to a simulation, including parameters, Fault Mode s, and Disturbances. Defined in
fmdtools.sim.scenario.Scenario.- Disturbances
A specific sequence of variable values over time which may modify system behavior.
- Sample
A set of scenario s to simulate a model over to represent certain hazards or parameters of interest. May be generated using
fmdtools.sim.sample.FaultSamplefor fault modes orfmdtools.sim.sample.ParameterSamplefor nominal parameters.- Nested Approach
The result of simulating a fault sampling Approach (
fmdtools.sim.sample.SampleApproach) within a nominal Approach (fmdtools.sim.sample.ParameterSample). Created infmdtools.sim.propagate.nested_sample().- Static Propagation
The undirected propagation of model behaviors within a timestep. Defined for each function using
fmdtools.define.block.Function.static_behavior(), which may run multiple times in a timestep until behavior has converged. The static behavior s are propagated through the graph using the methodfmdtools.define.architecture.function.FunctionArchitecture.prop_static().- Dynamic Propagation
The progression of model states over time. Defined for each function using
fmdtools.define.block.Function.dynamic_behavior(), which runs once per timestep. The dynamic behavior s are propagated using the methodfmdtools.define.block.Function.static_behavior(), which may run multiple times in a timestep until behavior has converged. The static behavior s are propagated through the graph using the methodfmdtools.define.architecture.function.FunctionArchitecture.propagate().- Propagation
The simulation of
fmdtools.define.architecture.function.FunctionArchitecturebehavior s, including the passing of flow s between function s and the progression of model states over time.- Resilience
The expectation of defined performance metrics over time over a set of hazardous scenario s, often defined in terms of the deviation from their nominal values.
- End-state
The state of a
fmdtools.define.block.base.Simulableat the final time-step of a simulation.- FMEA
A table outlining the risks of hazardous scenario s in terms of their rate, severity, and expected risk. By default, the
fmdtools.analyze.tabulatemodule produces cost-based FMEAS, with the metrics of interest being rate, cost, and expected cost, however these functions can be tailored to the metrics of interest.- Behavior Over Time
How a the states of a system unfold over time. Defined using behavior.
- Model History
A history of model states over a set of timesteps defined in
fmdtools.analyze.history.History. Returned in fmdtools as a nested dictionary from methods infmdtools.sim.propagate.- FRDL
- Architecture
Composition of blocks. Defined using
fmdtools.define.architecture.base.Architectureand its sub-classes.- Functional Reasoning Design Language
Language used to define/represent the network structure and behavioral propagation of an Architecture.
- Functional Architecture
Composition of Function and Flow objects in an overall Architecture that enables propagation of behaviors between function s.
Model Development Best Practices
Pay attention to and document the fmdtools version
As a research-oriented tool, much of the fmdtools interfaces can be considered to be “in development.” While we want to keep the repository stable, there have been many changes to syntax over the years to provide enhanced functionality and usages.
As such, it can be helpful to document what fmdtools version you are running in a README.md for your project, so you can always have a working model and replicate results, even if something has changed on the toolkit-level.
This also helps us (as developers) address bugs which affect specific versions of fmdtools, as well as identify bugs which were introduced in updates.
Plan your model to avoid technical debt
Simple, small models are relatively easy to define in fmdtools with a few functions, flows, and behaviors. As such, it can be easy to get in the habit of not planning or organizing development systematically, which leads to issues when developing larger models. Specifically, code that is written into existence instead of designed, planned, edited, tested, and documented. This leads to Technical debt, which is the inherent difficulty of modifying code that was written ad-hoc rather than designed. Unless this technical debt is resolved, the ability to modify a model (e.g., to add new behaviors, conduct analyses, etc) will be limited by the complicated and unwieldy existing code.
The next subsections give some advice to help avoid technical debt, based on lessons learned developing fmdtools models over the past few years.
Don’t copy, inherit and functionalize
Copy-and-paste can be a useful concept, but often gets over-relied upon by novice model developers who want to create several variants of the same programming structure. However, in the world of systems engineering (and software development), there are many cases where developers should be using class inheritance and writing functions instead.
The advantages of inheritance are:
It reduces the bulk amount of code required to represent functions, making code more comprehensible.
It makes the distinction between similar classes easier to distinguish, since there is no redundant code.
It makes it easier to edit code afterward, since the developer only has to edit in one place for it to apply to all the relevant types.
It makes testing easier, since common methods only need to be tested once.
In fmdtools, these patterns can be helpful:
Instead of creating two very similar
fmdtools.define.block.function.Functionclasses (e.g. Drone and PilotedAircraft) and copying code between each, create a single class (e.g. Aircraft) with common methods/structures (e.g., Fly, Taxi, Park, etc.) and then use sub-classes to extend and/or replace methods/structures in the common class as needed (e.g., Autonomous Navigation in the Drone vs. Piloted Navigation in the normal aircraft).Instead copying code for the same operations to several different places in a model, write a single function instead. This method can then be documented/tested and extended to a variety of different use-cases which require the same basic operation to be done.
This is an incomplete list. In general, it can be a helpful limitation to try to avoid using copy-and-paste as much as possible. Instead if a piece of code needs to be run more than once in more than once place, write a function or method which will be used everywhere. The idea should be to write the code once, and run it everywhere.
Document your code, sometimes before your write it
In general, Python coding style aspires to be as self-documenting as possible. However, this is not a replacement for documentation. In general, novice developers think of documentation as something which happens at the end of the software development process, as something to primarily assist users.
This neglects the major benefits of documentation in the development process. Specifically:
it helps other people understand how to use and contribute to your code,
it helps define what your code is supposed to do, its interfaces, and the desired behavior, and
as a result, it helps you understand your code.
For fmdtools models, documentation should at the very least take the following form:
A README (in markdown or rst) that explains how to set up the model environment (e.g., requirements/dependencies), as well as explains the structure of the folder/repo (model file, tests, analyses, etc.)
Documented examples of using the code. Usually you can use a jupyter notebook for this to show the different analyses you can run with your model.
- Docstrings document the classes and functions which make up your model. These are most important for development and should include:
An overall module description (top of file)
Docstrings for flows: What does the state represent? What are the states? What values may these take?
Docstrings for
fmdtools.define.block.function.Function: What are the states, parameters, behaviors, and modes?For any method/function, try to follow existing docstring conventions, with a summary of the purpose/behavior of the method, and a description of all input/output data types.
Documentation can best be thought of as a contract that your code should fulfill. As such, it can be very helpful to think of the documentation first, as a way of specifying your work. Tests (formal and informal) can then be defined based on the stated behavior of the function. It is thus recommended to document your code as you write it, instead of waiting until the end of the development process, to avoid technical debt.
Don’t get ahead of yourself–try to get a running simulation first
In the model development process, it can often be tempting to try to model every single mode or behavior in immense detail from the get-go. This is motivated by a desire to acheive realism, but can lead to issues from a project management and integration perspective. A model does not have much meaning outside a simulation or analysis, and, as such, development needs to be motivated first by getting a working simulation and then by adding detail. These simulations are the key feedback loop for determining whether model code is embodying desired behavior.
A very basic model development process should thus proceed:
Create Architecture file and create place-holder major function/flow classes
Connect classes in a Architecture file and visualize structure
Create low-fidelity model behaviors and verify in nominal scenario
Add hazard metrics in find_classification
Add more detailed behaviors (e.g., modes, actions, components, etc) as needed
Perform more complex analyses…
In general, it is bad to spend a lot of time developing a model without running any sort of simulation for verification purposes. This toolkit has been designed to enable the use of simulations early in the development process, and it is best to use these features earlier rather than later.
Finally, smaller, incremental iterations are better than large iterations. Instead of spending time implementing large sections of code at once (with documentation and testing TBD), instead implement small sections of code that you can then document, test, and edit immediately after. Using these small iterative cycles can increase code quality by ensuring that large blocks of undocumented/untested (and ultimately unreliable) code don’t make it into your project, only for you to have to deal with it later.
Preserve your prototype setup by formalizing it as a test
Testing code is something which is often neglected in the development process, as something to do when the project is finished (i.e., as an assurance rather than development task). Simultaneously, developers often iterate over temporary scripts and code snippets during development to ensure that it works as expected in what is essentially an informal testing process. The major problem with this process is that these tests are easily lost and are only run one at a time, making it difficult to verify that code works after it has been modified.
Instead, it is best to formalize scripts into tests. This can be done with Python’s unittest module, which integrates well with existing python IDEs and enables execution of several different tests in a sequence. Instead of losing prototype code, one can easily place this code into a test_X method and use it iteratively in the development process to ensure that the code still works as intended. This is true even for more “qualitative” prototype script, where the output that is being iterated over is a plot of results. Rather than abandoning a prototyping setup like this, (e.g., by commenting it out), a much better approach is to formalize the script as a test which can be run at the will of the user when desired. In this case, the plot should show the analysis and describe expected results so that it can be quickly verified. The testing of plots is enabled with the function fmdtools.analyze.common.suite_for_plots(), which enables you to filter plotting tests out of a model’s test suite (or specify only running specific tests/showing specific plots).
While testing is an assurance activity, it should also be considered a development activity. Testing ensures that the changes made to code do not cause it to take on undesired behaviors, or be unable to operate with its interfacing functions. To enable tests to continue to be useful through the modelling process, they should be given meaningful names as well as descriptions describing what is being tested by the test (and why).
Finally, do not create tests solely to create tests. Tests should have a specific purpose in mind, ideally single tests should cover as many considerations as possible, rather than creating new tests for each individual consideration. As in model development, try to avoid bloat as much as possible. If the desire is to cover every edge-case, try to parameterize tests over these cases instead of creating individual test methods.
Edit your code
The nature of writing code is a messy process–often we spend a considerable amount of time getting code to a place where it “works” (i.e., runs) and leave it as-is. The problem with doing this over and over is that it neglects the syntax, documetation, and structural aspects of coding and thus contributes to technical debt. One of the best ways to avoid this from impacting development too much is to edit code after writing it.
Editing is the process of reviewing the code, recognizing potential (functional and stylistic) problems, and ultimately revising the code to resolve these problems. In this process, all of the following concerns should be considered:
Do the data structures make logical sense? Are they used systematically throughout the project?
Are operations organized with a logical structure? Is it easy to see what is performed in what sequence? Are lines too long?
Are naming and stylistic conventions being followed? Do variables have self-explanatory names? Are names being spelled correctly?
Are lines too long? Are there too many nested statements?
Are the methods/classes fully documented?
Will the functions work in every possible case implied by the documentation?
Is inheritance being used correctly?
Is the code re-inventing existing fmdtools structure or syntax or going against existing protocols?
Does it pass all tests?
This is an incomplete list. The point is to regularly review and improve code after it is implemented to minimize future technical debt. Waiting to edit will cause more hardship down the line.
Structuring a model
fmdtools was originally developed around a very simple use-case of modeling physical behaviors using a Function/Flow ontology, where Functions (referred to as “technical functions”) are supposed to be the high-level roles to be performed in the system, while flows are the data passed between these roles (energy, material, or signal). Many of the models in the repository were developed to follow this form, or some variation of it, however, more complex modeling use-cases have led us to expand our conception of what can/should be modeled with a function or flow. More generally,
Flows define shared data structures, meaning interacting variables and
Functions define behaviors, meaning things to be done to flows.
These functions and flows are connected via containment relationships in an undirected graph, meaning that functions can be run in any order within a time-step to enable faults to propogate throughout the model graph. This is a very general representation, but also leads to pit-falls if the model is too complex, since this behavior needs to be convergent within each timestep. The following gives some advice for conventions to follow in models based on their size/scope.
Small Models
Small models have a few functions with simple behaviors that are being loaded in simple ways. A good example of this is the Pump Example and EPS Example , where the model is a simple translation of inputs (defined in input functions) to outputs (defined in output functions). These models have the most ability to follow the Functional Basis modeling ontology <https://link.springer.com/article/10.1007/s00163-001-0008-3>_ (with import_x being inputs and output_x being outputs of the system), as well as use static_behavior methods. It is also possible to model many different modes with full behavioral detail, since the system itself is not too complicated. Technical debt and development process is less of a consideration in these models, but should still not be ignored. A typical structure for a model would be:
- Architecture
- flows
X
Y
- functions
Import_X
Change_X_to_Y
Export_Y
System Models
Moderate-size system models are models which have a control/planning system (e.g., something that tells it what to do at any given time). They also often interact with their environment in complex ways. A typical structure for a model would be:
- Architecture
- flows
Environment, Location, etc (place the system is located in and its place in it)
Power, Actions, etc (internal power/other physical states)
Commands,Communications, etc (external commands/comms with an operator)
- functions
Affect_Environment (Physical behaviors the system performs on the environment)
Control_System (Controls, Planning, Perception, etc)
Distribute_Energy, Hold_X, etc (Internal components, etc)
A good example of this are the Drone and Rover models. Models like this are simply more complex and thus require more care and attention to avoid the accumulation of technical debt. It may be desireable for some of the more complex functions to be specified tested in isolation, and developed in their own files. Finally, flows such as Environment may require developing custom visualization methods (maps, etc) to show the how the system interacts with its environment.
System of Systems Models
Systems of Systems models involve the interaction of multiple systems in a single model. These models are much more complex and thus require very good development practices to develop to maturity. A typical structure for a model for this might be:
- Architecture
- flows
Environment (place the systems are located in)
Location(s) (individual states of the agents)
Communication(s) (agent interactions with each other
- functions
Asset/Agent(s) (individual system models)
AgentController(s) (coordinator which issues commans to each system)
Note that, unlike other model types, System of Systems models very often will have multiple copies of functions and flows instantiated in the model. As a result, it is important to use dedicated model structures to the overall structure from being intractible. Specifically, multiple copies of flows can be handled using the MultiFlow class while Communications between agents can be handled using the CommsFlow class. The ModelTypeGraph graph representation can be used to represent the model as just the types involved (rather than all instantiations). In general, it can be helpful to create tests/analyses for individual agents in addition to the overall system.
Use model constructs to simplify your code
The fmdtools codebase is quite large, and, as a result, it can be tempting to dive into modeling before learning about all of its capabilities. The problem with this is that many of these capabilities and interfaces are there to make your life easier, provided you understand and use them correctly. Below are some commonly-misunderstood constructs to integrate into your code:
fmdtools.define.container.base.BaseContainerhas a number of very basic operations which can be used in all containers to reduce the length of lines dedicated solely to assignment and passing variables between constructs. Using these methods can furthermore enable one to more simply perform vector operations with reduced syntax.fmdtools.define.object.timer.Timercan be used very simply to represent timed behavior and state-transitions.While modes can be used to describe fault modes in a very general way, faulty behavior that can also be queried from the model using the concept of a disturbance, which is merely a change in a given variable value. While disturbances are less general, they require much less to be implemented in the model. Disturbances can be passed as an argument (as a dict or as a part of a Sequence class) to
fmdtools.sim.propagate.sequence()fmdtools.define.container.parameter.Parameterand parameter-generating functions are helpful for understanding the model operating envelope. In general, try to avoid having parameters that duplicate each other in some way.Randomness can be used throughout, but use the specified interfaces (
fmdtools.define.container.rand.Rand, etc.) so that a single seed is used to generate all of the rngs in the model. Not using these interfaces can lead to not being able to replicate results consistently.A variety of custom attributes can be added to
fmdtools.define.block.function.Functionandfmdtools.define.flow.base.Flow, but not every custom attribute is going to work with staged execution and parallelism options. In general, use containers to represent things that change and parameters to represent things that don’t change. If you want to do something fancy with data structures, you may need to re-implementfmdtools.define.block.basemethods for copying and returning states to propagate.If there’s something that you’d like to do in an fmdtools model that is difficult with existing model structures, consider filing a bug report before implementing an ad-hoc solution. Alternatively, try devoping your solution as a feature rather than a hack to solve a single use-case. If the features is in our scope and well-developed, we may try to incorporate it in our next release.
Style advice
Development of fmdtools models should follow the PEP 8 Style Guide as much as possible. While this won’t be entirely re-iterated here, the following applies:
- Use CamelCase for classes like
fmdtools.define.architecture.function.FunctionArchitecture,fmdtools.define.block.function.Function,fmdtools.define.flow.base.Flow, etc. Use lowercase for object instantiations of these classes, and lower_case_with_underscores (e.g. do_this()) for methods/functions. if a model class is named Model (e.g., Drone), the instance can be named model_X, where X is an identifying string for the model being used (e.g. drone_test).
- Use CamelCase for classes like
Names should be descriptive, but keep the length down. Use abbreviations if needed.
Try to use the code formatting structure to show what your code is doing as much as possible. Single-line if statements can be good for this, as long as they don’t go too long.
Python one-liners can be fun, but try to keep them short enough to be able to read.
If a file is >1000 lines, you may want to split it into multiple files, for the model, complex classes, visualization, analysis, tests, etc.
fmdtools lets you specify names for functions/flows. Keep these consistent with the class names but consider making them short to enable visualization on model graphs and throughout the code.
It’s fmdtools. Not Fmdtools or fmd tool. Even when it starts the sentence.
See also
How to Contribute
Development of fmdtools is coordinated by the fmdtools team at NASA Ames Research Center. As an open-source tool developed under the NASA Open Source Agreement, outside contributions are welcomed. To be able to submit contributions (e.g., pull requests), external contributors should first submit a contributors license agreement (Individual CLA , Corporate CLA).
Repo Structure

Getting started with development first requires some basic familiarity with the repo structure, shown above. As shown, the repo contains:
/fmdtools, which is where the toolkit sub-packages and modules are held,/tests, which has tests of the modules,/examples, which are different case study examples, and/docs, which contains documentation.
There are additionally a few scripts with specific purposes to serve the development process:
run_all_tests.pywhich is a script that runs tests defined in /tests and /examples,setup.py, which is used for building PyPI packages, andMAKE, which is used to build the sphinx documentation.
Remote Structure

Development of fmdtools uses a two-track development model, in which contributions are provided within NASA as well as by external collaborators. To support this, there are multiple repositories which must be managed in the development process, as shown above. Essentially, there is:
An internal bitbucket, where NASA coordination and development takes place,
A public GitHub, where collaboration with outside developers takes place (and where documentation is hosted), and
A PyPI repository which contains stable versions of fmdtools which can be readily installed via
pip.
The fmdtools team is responsible for coordinating the development between the internal and external git repositories. Managing multiple repositories can best be coordinated by:
setting up multiple remotes on a single git repo on your machine using git remote and
propagating changes between repositories during development using git push and git pull from each repository
Development Process

To encourage code quality we follow the general process above to manage contributions:
Development begins on a
/devbranch for a given version of fmdtools. This branch is used to test and integrate contributions from multiple sources.The first step in making a contribution is then to create an issue, which describes the work to be performed and/or problem to be solved.
This issue can then be taken on in an issue branch (or repo for external contributions) and fixed.
When the contributor is done with a given fix, they can submit a pull request, which enables the review of the fix as a whole.
This fix is reviewed by a member of the fmdtools team, who may suggest changes.
When the review is accepted, it is merged into the
devbranch.When all the issues for a given version are complete (this may also happen concurrently with development), tests and documentation are updated for the branch. If tests do not pass (or are obsolete), contributions may be made directly on the
devbranch to fix it, or further issues may be generated based on the impact of the change.When the software team deems the release process to be complete, the
devbranch may be merged into the main branch. These branches are then used to create releases.
The major exceptions to this process are:
bug fixes, which, if minor, may occur on
main/devbranches (or may be given their own branches off ofmain),external contributions, which are managed via pull request off of
main(or some external dev branch), andminor documentation changes.
Release Checklist
When releasing fmdtools, follow the steps in the Release Checklist, see below:
Step |
Description |
Complete? |
Comment |
|---|---|---|---|
1 |
Sync appropriate branches into release branch |
||
1a |
|
||
1b |
|
||
2 |
Run script run_all_tests.py and verify test results are appropriate |
||
2a |
|
||
2b |
|
||
3 |
Update version numbers in appropriate files |
||
3a |
|
||
3b |
|
||
4 |
Generate the documentation using “./make html” |
||
5 |
Commit and tag branch with the appropriate version. |
||
5a |
|
||
6 |
Sync to remotes |
||
6a |
|
||
6b |
|
||
7 |
Create a release in GitHub |
||
7a |
|
||
7b |
|
||
8 |
|
||
8a |
|
||
8b |
|
||
8c |
|
||
9 |
Update/check external CI resources as needed |
||
9a |
|
||
10 |
If release is ‘stable’ Upload to PyPI (see below |
Upload to PyPI
Note: Performing this process requires an account with the Python Package Index and Owner/Maintainer status in the fmdtools repository. Presently, this repository is owned by Daniel Hulse and setup should be coordinated with him.
Note: Performing this process also requires a twine setup. For full instructions, see: https://www.geeksforgeeks.org/how-to-publish-python-package-at-pypi-using-twine-module/
Once this is set up, the code can be built and uploaded using the following commands in powershell from the repository folder:
python -m build
python -m twine check dist/*
python -m twine upload –repository pypi dist/*
Note: when performing for the first time, it may be helpful to use the test python repo (substitute testpypi for pypi) first—an account is required however.
Note: make sure that there are no old versions in dist/
After upload, test the deployment by:
Spot-checking the online repo (e.g., has the version updated?)
Updating the package (
pip install –upgrade pip)
Roles
team lead: coordinates all activities and has technical authority over project direction
full developer: can make changes off of version and main branches and has full ability to perform the release process
contributor: creates issues and develops off of issue branches
Documentation
Documentation is generated using Sphinx, which generates html from rst files. The process for generating documentation (after sphinx has been set up) is to open powershell and run:
cd path/to/fmdtools
./make clean
./make html
Note that sphinx requires the following requirements, which should be installed beforehand:
nbsphinx
myst_parser
sphinx_rtd_theme
pandoc
Pandoc must be installed with anaconda (i.e., using conda install pandoc) since it is an external program.
Style/Formatting
Generally, we try to follow PEP8 style conventions. To catch these errors, it is best to turn on PEP8 style linting in your IDE of choice.
Style conventions can additionally be followed/enforced automatically using the Black code formatter. See resources:
stand-alone formatter: https://github.com/psf/black
VSCode Extension: https://marketplace.visualstudio.com/items?itemName=ms-python.black-formatter
Spyder workflow: https://stackoverflow.com/questions/55698077/how-to-use-code-formatter-black-with-spyder
Testing
There are two major types of tests:
quantitative tests, which are tests running
run_all_tests.py, andqualitative tests, which are the example notebooks