Trigger a Workflow Execution
To trigger a workflow, you need to create a rule. To trigger an ingest workflow, one that requires discovering and ingesting data, you will also need to configure the collection and provider and associate those to a rule.
Trigger a HelloWorld Workflow
To trigger a HelloWorld workflow that does not need to discover or archive data, you just need to create a rule.
You can leave the provider and collection blank and do not need any additional metadata. If you create a onetime rule, the workflow execution will start momentarily and you can view its status on the Executions page unless it was created with a DISABLED state.
Trigger an Ingest Workflow
To ingest data, you will need a provider and collection configured to tell your workflow where to discover data and where to archive the data respectively.
Follow the instructions to create a provider and create a collection and configure their fields for your data ingest.
In the rule's additional metadata you can specify a provider_path from which to get the data from the provider.
Example: Ingest data from S3
Setup
Assume there are 2 files to be ingested in an S3 bucket called discovery-bucket, located in the test-data folder:
- GRANULE.A2017025.jpg
- GRANULE.A2017025.hdf
Archive buckets should already be created and mapped to public / private / protected in the Cumulus deployment.
For example:
buckets = {
private = {
name = "discovery-bucket"
type = "private"
},
protected = {
name = "archive-protected"
type = "protected"
}
public = {
name = "archive-public"
type = "public"
}
}
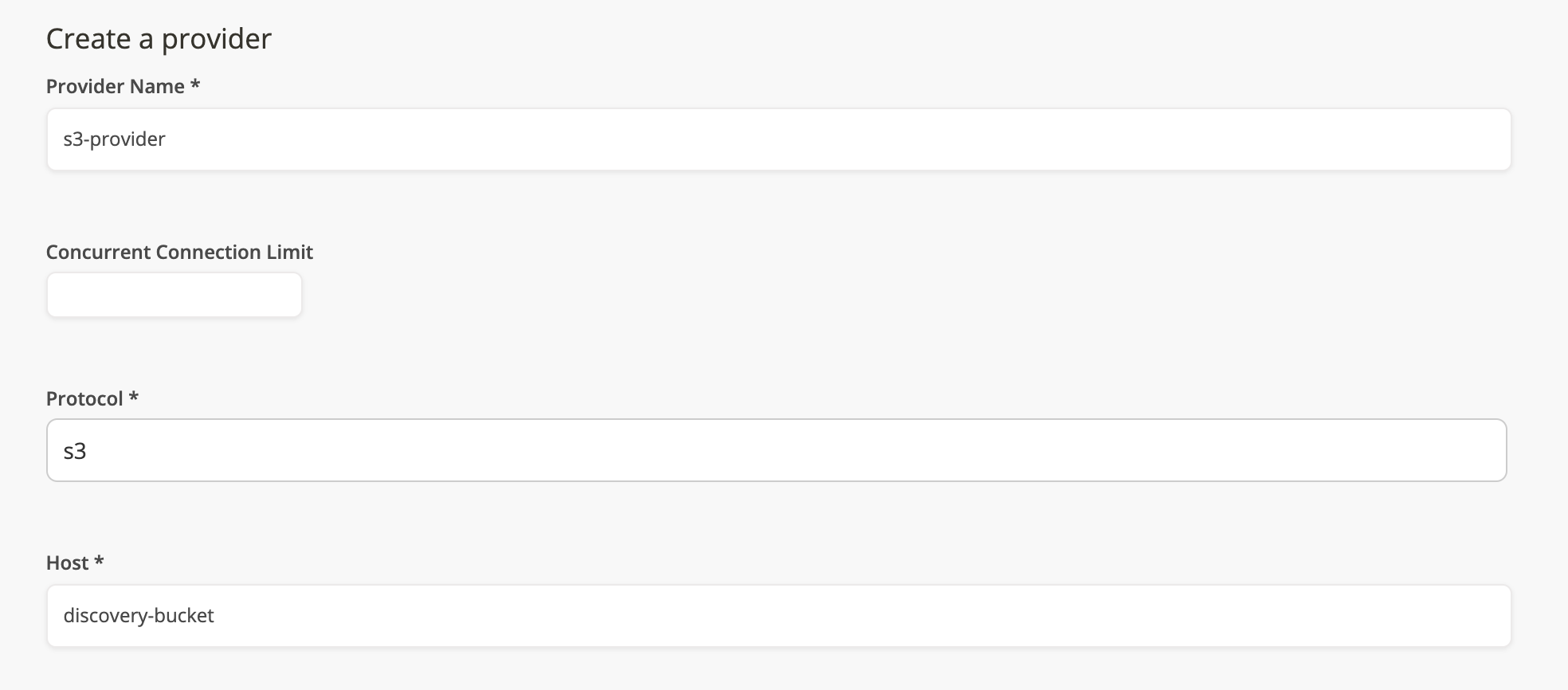
Create a provider
Create a new provider. Set protocol to S3 and Host to discovery-bucket.
Create a collection
Create a new collection. Configure the collection to extract the granule id from the filenames and configure where to store the granule files.
The configuration below will store hdf files in the protected bucket and jpg files in the private bucket. The bucket types are
{
"name": "test-collection",
"version": "001",
"granuleId": "^GRANULE\\.A[\\d]{7}$",
"granuleIdExtraction": "(GRANULE\\..*)(\\.hdf|\\.jpg)",
"reportToEms": false,
"sampleFileName": "GRANULE.A2017025.hdf",
"files": [
{
"bucket": "protected",
"regex": "^GRANULE\\.A[\\d]{7}\\.hdf$",
"sampleFileName": "GRANULE.A2017025.hdf"
},
{
"bucket": "public",
"regex": "^GRANULE\\.A[\\d]{7}\\.jpg$",
"sampleFileName": "GRANULE.A2017025.jpg"
}
]
}
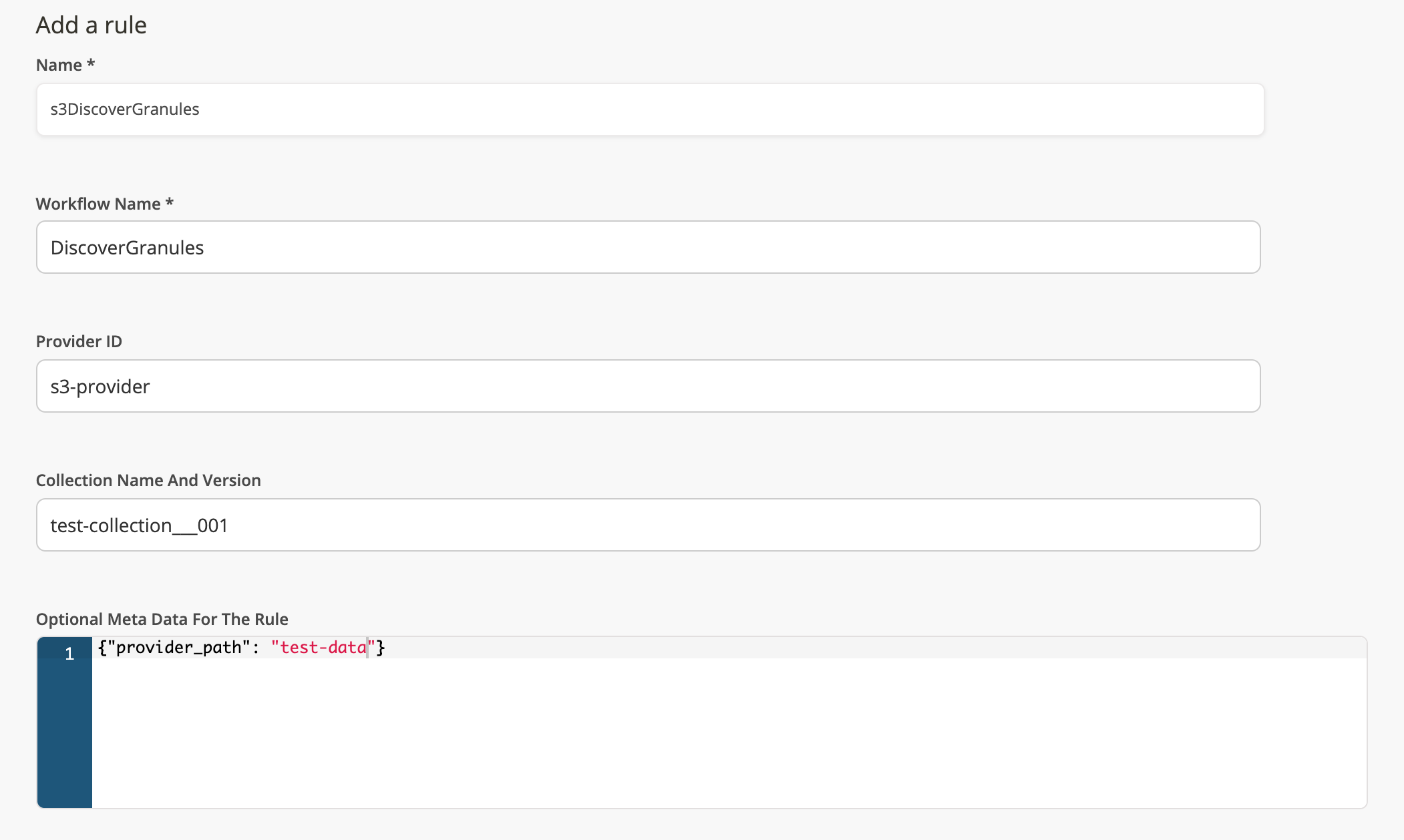
Create a rule
Create a rule to trigger the workflow to discover your granule data and ingest your granule.
Select the previously created provider and collection. See the Cumulus Discover Granules workflow for a workflow example of using Cumulus tasks to discover and queue data for ingest.
In the rule meta, set the provider_path to test-data, so the test-data folder will be used to discover new granules.
A onetime rule will run your workflow on-demand and you can view it on the dashboard Executions page unless it has a DISABLED state. In order to run a workflow with a onetime DISABLED rule, please change the rule state to ENABLED and re-run. The Cumulus Discover Granules workflow will trigger an ingest workflow and your ingested granules will be visible on the dashboard Granules page.