Granule Uniquification Feature
Overview
The Granule Uniquification feature in Cumulus allows for the ingestion and management of multiple granules that share the same granuleId but belong to different collections. This is achieved by creating a unique granuleId for each granule and storing the original, non-unique identifier in a new field called producerGranuleId.
This feature is critical for systems migrating from ECS and other workflows where granuleId may not be globally unique. Existing workflows that have no need for this feature should be compatible with no changes, however the end result will be the granuleId and producerGranuleId will be set to the same value if producerGranuleId is not specified.
This feature was added in Cumulus version 21, this document provides an overview of the feature and high level changes associated with the feature from previous versions.
Technical Approach
The changes included with this feature make updates to the Cumulus database schema, granule read/write/reporting components and workflow task components.
The intent is to modify the Cumulus database and framework to handle tracking both a unique identifier granuleId and provide a granule object field producerGranuleId that tracks an identifier from the data producer/provider that may not be unique.
In concert with those updates, Cumulus task components that generate granule objects have been updated to optionally be configured to 'uniquify' granule objects by generating a unique granuleId and storing the original granuleId value in the producerGranuleId field.
Adding 'uniquification' to Ingest Workflows
The process of updating or creating an ingest workflow that makes use of this feature should follow the following high-level guidelines:
-
If providers/pre-ingest processing provides
producerGranuleIdas part of the granule object and pre-uniquifies the graunleId, Core task components will 'do the right thing' out of the box. -
Ingest workflows that have incoming granules that have only granuleId populated will need to make use of the updated Cumulus workflow task components or make updates to other in-use functions to make the granuleId unique as appropriate. For details on this, please see the following:
-
hashing approach document for details on the approach Cumulus components that create a
granuleIdare using. Please also review the added task component -
AddUniqueGranuleIdthat can be utilized in workflows to update a granule with a uniquegranuleId, saving the 'original' asproducerGranuleId.
-
-
Workflows that start with a Cumulus message (not a CNM message or other format) with a payload containing granules but intend to change the ID as part of the workflow will need to reconfigure Cumulus to not report the initial granules prior to workflow steps that update the granule to have a unique Id and optionally update the workflow to report them as running following that uniquification using
SfSqsReportTask. See Record Write Options feature doc for more information.
Important: User task components, particularly any that re-implement core reference tasks, must be evaluated carefully to ensure consistent behavior in instances where the granuleId has been modified.
The following diagram shows expected flow and potential modification considerations for a typical ingest flow, with orange being components that may need modification/update to make use of this feature, and green representing updated Core task components:
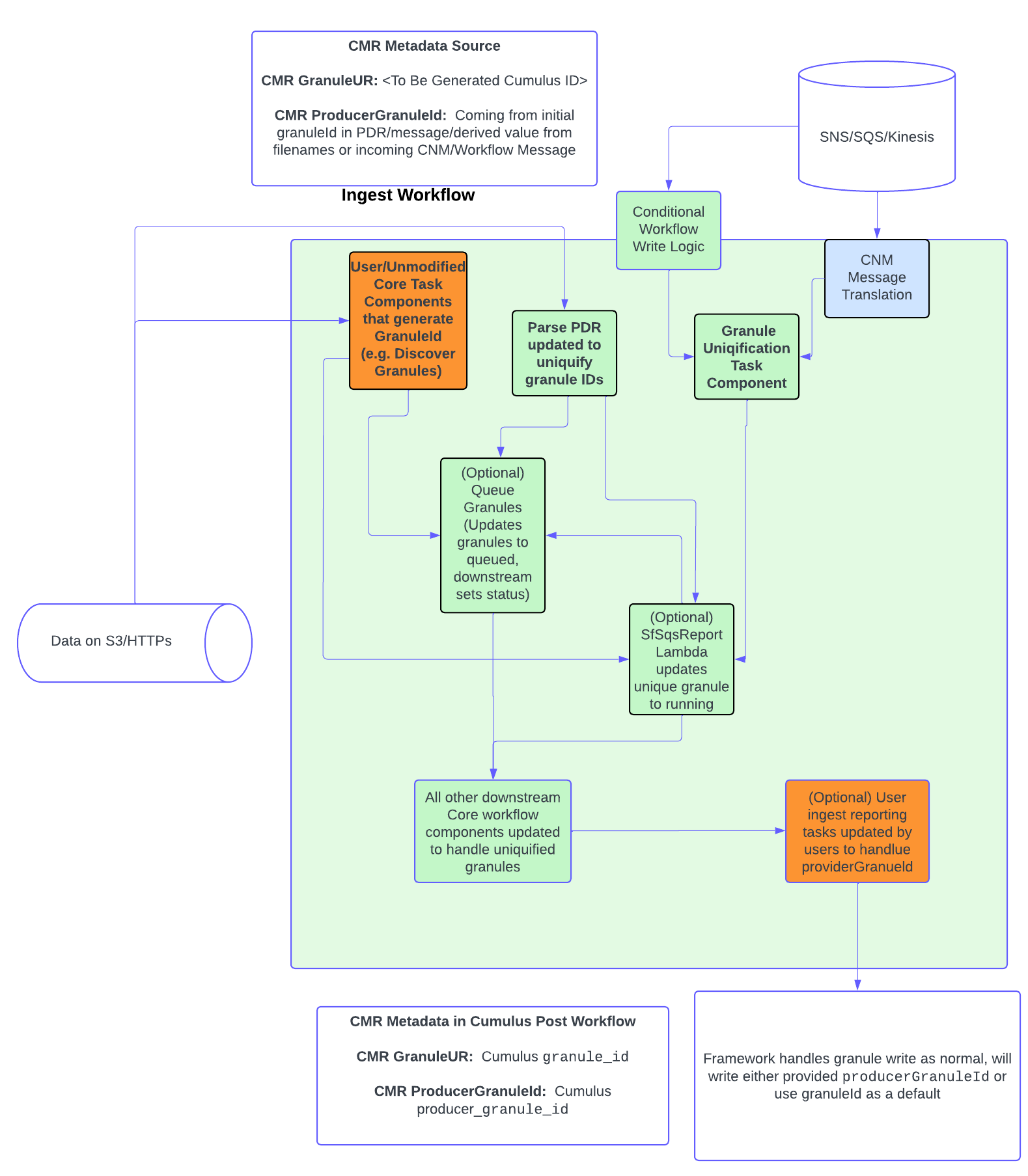
Uniquification Methodology
Optimally, adding a uniqueGranuleId and populating a relevant producerGranuleId in incoming granules should be done prior to ingest into Cumulus. Cumulus maintained workflow tasks have been updated to handle incoming messages with producerGranuleId and granuleId appropriately.
If that's not possible due to filename based discovery ingest, or provider process restrictions, the updated task components allow an in-workflow approach to making granuleIds unique.
When a workflow is configured to utilize any of the modified tasks that generate a unique ID, Cumulus workflow tasks use a hashing algorithm to generate a unique suffix that is appended to the original granuleId. This process is handled by the add-unique-granule-id task, is integrated into some tasks (e.g. parse_pdr), or relevant user tasks can be updated as well.
The recommended algorithm generates an MD5 hash of the granule's collectionId (and optionally a timestamp) and appends a truncated version of this hash to the producerGranuleId to create the new unique granuleId.
The process Cumulus Core uses to generate a unique granuleId can be found in the generateUniqueGranuleId function.
For more details on the algorithm and for implementations in other languages, see the Hashing approach document
There is no requirement to utilize Core's algorithm, as the workflow framework imposes no constraints outside of ensuring producerGranuleId is populated by a default, however if customization is desired, care should be taken to ensure that unique identification schemes are chosen such that unexpected collisions between granules do not occur system-wide.
To make the process easier, Cumulus Core also provides a Task Component that will uniquely identify each Granule in a payload and return a modified Granule object containing a unique granuleId and a producerGranuleId containing the original granuleId - AddUniqueGranuleId
External Impacts
Deploying a version of Cumulus with this feature enabled will result in the following impacts to downstream ecosystem as of when this document was last updated:
- CMR - Exported CMR metadata will now have UMMG/XML appropriate metadata populating the
ProducerGranuleIdin workflows that make use of theUpdate Granules CMR Metadata File Linkstask. For more information/specifics see the task README - Metrics - Granule objects newly ingested/updated will have the
producerGranuleIdfield populated - Lzards - Granules ingested using the updated task component will now have
producerGranuleIdfield populated as part of the LZARDS metadata. - Orca - no impacts, pending Orca updates that make use of the new field
Migration From Prior Versions
Users migrating to the release using this feature will need to migrate their database to make use of and populate the new producer_granule_id field in the Postgres database. Details of this transition are documented in the upgrade notes document.
Existing Workflow Updates
For existing ingest workflows/processes not wishing to update, the only functional changes are:
- The framework (post workflow event driven writes) populating a granule's
producerGranuleIdgranule field with the value from thegranuleIdfield if one is not provided as part of the ingest workflow. UpdateGranulesCmrMetadataFileLinkswill update the CMR metadata to include the newproducerGranuleIdin the CMR metadata.
Core Changes
The following sections detail changes to Cumulus Core as part of this feature:
Schema Changes
granuleId: This field remains unchanged in the Core schema, and remains a unique identifier for a granule within the Cumulus system. For granules that originally had a differentgranuleIdvia Cumulus Core Task Components or a provider provided identifier, this value will be a combination of the originalgranuleIdand a configurable hash.
Downstream consumers of Cumulus granule objects should not need to make modifications related to this field. Core will be moving away from API and other concepts that relate to identifying granule objects by granuleId + collectionId in future versions.
producerGranuleId: This new field is intended to store the original, non-unique producer granule identification value. This allows for traceability and correlation with the provider's source data.
If using Cumulus Core reference Task Components this value will be retained from the original granuleId. If using another process, or the provider is providing uniquified IDs, it's expected that producerGranuleId will be populated with an appropriate value.
Downstream consumers of Cumulus granules objects should update to make use of this field if they intend to directly reference producerGranuleId or need to reconcile their records to provider records directly.
Updated MoveGranules 'duplicate' handling behavior
Move Granules was updated to validate if an archive location object collision is due to a same-collection or cross-collection collision. If the collision is cross-collection, it will fail regardless of the collection configuration, to avoid inadvertent overwrites per requirements in IART-924.
Updated Workflow Task Component Modifications
The following tasks have been added or updated from prior versions to handle and/or allow conversion to use the new producerGranuleId field for this feature. All Core workflow tasks that utilize a granule payload were updated to allow for producerGranuleId in the granule object schema, and are not individually listed here if that was the only update.
Please refer to the README and schemas for the tasks as the source of truth regarding configuration options, this information is true at the time of feature implementation:
Added
AddUniqueGranuleId
Task was added to provide a 'shim' option to allow for incoming granules without a producerGranuleId to be uniqified as part of a workflow. A new ID is created and stored as the unique granuleId, with the original ID in the incoming granule retained in the producerGranuleId field. For details on the hashing approach used in this function see: hashing approach document
Updated
LzardsBackup
- Task was updated to include
producerGranuleIdas part of the LZARDSmetadataobject
ParsePdr
- Task was updated to take an optional configuration parameter
uniquifyGranulesthat if set totruewill update the granuleId for all found granules to have a unique granule hash appended to the existing ID (PR #3968). - Task was updated to always populate producerGranuleId for the output granule with the incoming producerGranuleId.
- Task was updated to detect duplicate granuleIds and throw an error if uniquification is not enabled.
QueueGranules
- Task was updated to set
producerGranuleIdtogranuleIdif not set in the input granules (PR #3968)
UpdateGranulesCmrMetadataFileLinks
- Task was updated to always set
granuleURandproducerGranuleIdin the CMR metadata file based on the passed in granule. (PR #3997)
FilesToGranules
- Task was updated to allow
producerGranuleIdin the granule schema, and addedmatchFilesWithProducerGranuleIdas a configuration flag
Updated Cumulus Framework Behaviors
- The API will now allow for updates/writing of
producerGranuleId. This field is set either to the incoming value in the granule object or defaults to the value forgranuleId. - Granule PUT, GET, PATCH and POST will allow for
producerGranuleIdto be set. producerGranuleIdwill be output from all calls that output a granule object, and update SNS topics will report them to downstream consumers as well
Workflow Feature Use
Collection Configuration
Most of the task Granule uniquification options in the updated task components can be enabled and configured at the collection level using meta , or optionally be provided via workflow configuration or a rule meta field.
As an example, collection oriented configuration can be achieved in the AddUniqueGranuleId implementations by adding the following to the collection.meta object:
"meta": {
"uniquifyGranuleId": true,
"hashLength": 8
}
Once you've done that, you can then add task configuration hooks to the workflow components that need configuration:
"AddUniqueGranuleId": {
"Parameters": {
"cma": {
"event.$": "$",
"ReplaceConfig": {
"Path": "$.payload",
"TargetPath": "$.payload"
},
"task_config": {
"hashLength": "{$.meta.collection.meta.hashLength}"
}
}
},
If uniquifyGranuleId is true and the Collection is ingested using a workflow that includes the AddUniqueGranuleId Task (required to update the granuleId), the granuleId will be uniquely generated using the generateUniqueGranuleId function here. The hashLength specifies how many characters the randomized hash contains. More characters offer a greater chance of uniqueness.
Here is an example workflow configuration including the AddUniqueGranuleId task.
Collection Path Considerations
A Collection that is configured to uniquely identify Granules in this way means that the existing granuleId will change to a unique, hashed value. This is important to consider when building workflows and, in particular, specifying the S3 paths for a Granule's Files. This is also true for all workflows that may be run with Granules that have previously had their granuleId uniquely generated
In a Collection configuration, you can specify the url_path template that will be used to determine the final location of the Collection's Files if using the MoveGranules Task Component.
If that path contains a granuleId or anything derived from granuleId, notably the CMR Metadata's GranuleUR, that path will contain the unique value. An example containing the unique granuleId might look like:
"url_path": "{cmrMetadata.Granule.Collection.ShortName}___{cmrMetadata.Granule.Collection.VersionId}/{granule.granuleId}",
or
"url_path": "{cmrMetadata.Granule.Collection.ShortName}___{cmrMetadata.Granule.Collection.VersionId}/{cmrMetadata.Granule.GranuleUR}",
If that is NOT desirable and using the original, non-unique value is preferred, that is still possible. The Collection would need to be configured to use the producerGranuleId, which represents the original granuleId value without any uniquification, or a completely different value.
"url_path": "{cmrMetadata.Granule.Collection.ShortName}___{cmrMetadata.Granule.Collection.VersionId}/{granule.producerGranuleId}/",
Taking it a step further, depending on the workflow configuration, users can specify a default using the defaultTo operation if the producerGranuleId isn't available for a given Granule.
"url_path": "{cmrMetadata.Granule.Collection.ShortName}___{cmrMetadata.Granule.Collection.VersionId}/{defaultTo(granule.producerGranuleId, granule.granuleId)}",
Workflow Configuration
An additional consideration to configuring the collection to uniquely identify granules is the record writing mechanism in the Cumulus Core framework.
When a workflow executes, records are written to the Cumulus datastore including execution, granule, and pdr (among others). These records are written and updated to reflect the stages of the workflow execution. Initially a granule (for example) will be written in the running state. As the workflow progresses, that granule will be updated to either completed or failed. This presents a potential issue if the Cumulus workflow is generating a unique ID for the incoming granule as the initial write (a granule written as running) will happen before the workflow task is able to generate the unique ID. The resulting record will reflect the original, non-unique granuleId e.g.
{
"granuleId": "L2_HR_PIXC_A"
}
After the Granule has been assigned a unique granuleId in the add-unique-granuleID task the payload will look similar to this:
{
"granuleId": "L2_HR_PIXC_A_zHGdMM",
"producerGranuleId": "L2_HR_PIXC_A"
}
Where the granuleId is now a unique value and the original granuleId is stored as producerGranuleId.
In this case, it may be desirable to to skip that initial record write as we do not want to attempt to write a granule with a granuleId that 1. may conflict with another and 2. does not represent the final granuleId, which could result in extraneous records.
To configure the workflow to skip that initial granule write (when the granule is in the running state), the workflow can be configured using the sf_event_sqs_to_db_records_types block in the Terraform configuration. In this example using the IngestAndPublishGranule workflow, the configuration would be:
{
sf_event_sqs_to_db_records_types = {
IngestAndPublishGranule = {
running = ["execution", "pdr"]
}
}
}
execution and pdr records will be written in the running state. granule will not because it is not specified. As of this writing, execution and pdr must always be written. granule is currently the only record type that can be skipped in this way. This behavior is subject to change in the future, see below documentation for the most current Record Write Options.
Important: If skipping the initial Granule record write is desired in a PDR workflow, additional modification may be required. See the Record Write Options documentation for details on this use case as well as general documentation on skipping record writes.
Workflow Examples
SIPS/PDR Based Workflow
Documentation in the "SIPS" Workflow Cookbook outlines an example usage of DiscoverPDRs, QueuePDRs and ParsePDR in a workflow. As mentioned above, uniquification should be a simple matter of configuring ParsePDR with appropriate uniquification configuration values.
CNM/Kinesis Style Ingest Workflow
Cumulus's integration deployment provides an example of a CNM style workflow which is detailed in a "cookbook" that can be used for both uniquified and non-uniquified collections. This workflow is a typical single-workflow ingest using a Kinesis stream that is triggering workflows with a CNM message, but it uses a choice state to configurably use the AddUniqueGranuleId task in the workflow for collections that are configured to handle this in-workflow:
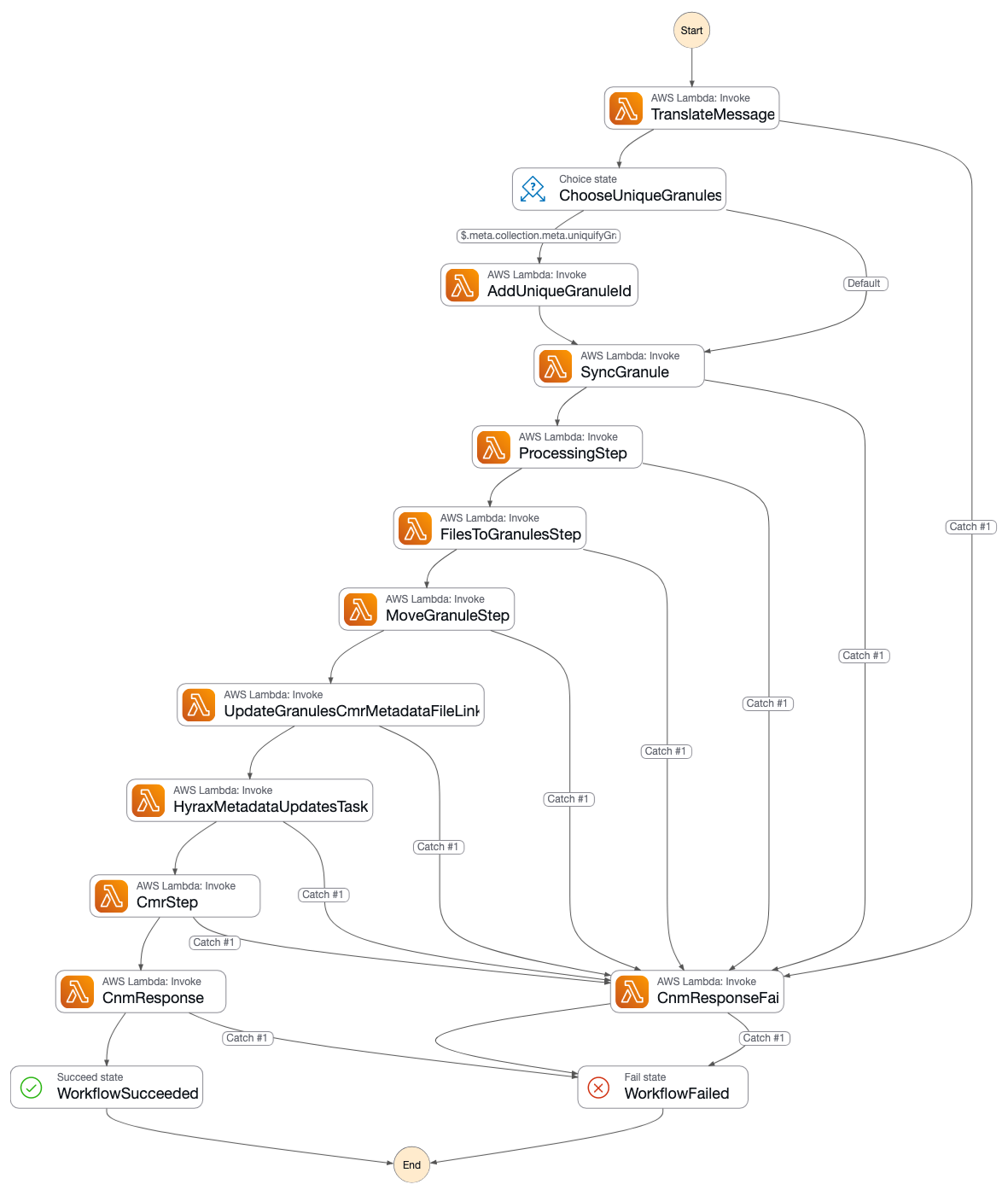
Downstream steps have the relevant configuration values wired in from the collection configuration for steps that require it. For example the integration test "ProcessingStep":
"task_config": {
"bucket": "{$.meta.buckets.private.name}",
"collection": "{$.meta.collection}",
"cmrMetadataFormat": "{$.meta.cmrMetadataFormat}",
"additionalUrls": "{$.meta.additionalUrls}",
"matchFilesWithProducerGranuleId": "{$.meta.collection.meta.uniquifyGranuleId}"