Architecture
Architecture
Below, find a diagram with the components that comprise an instance of Cumulus.
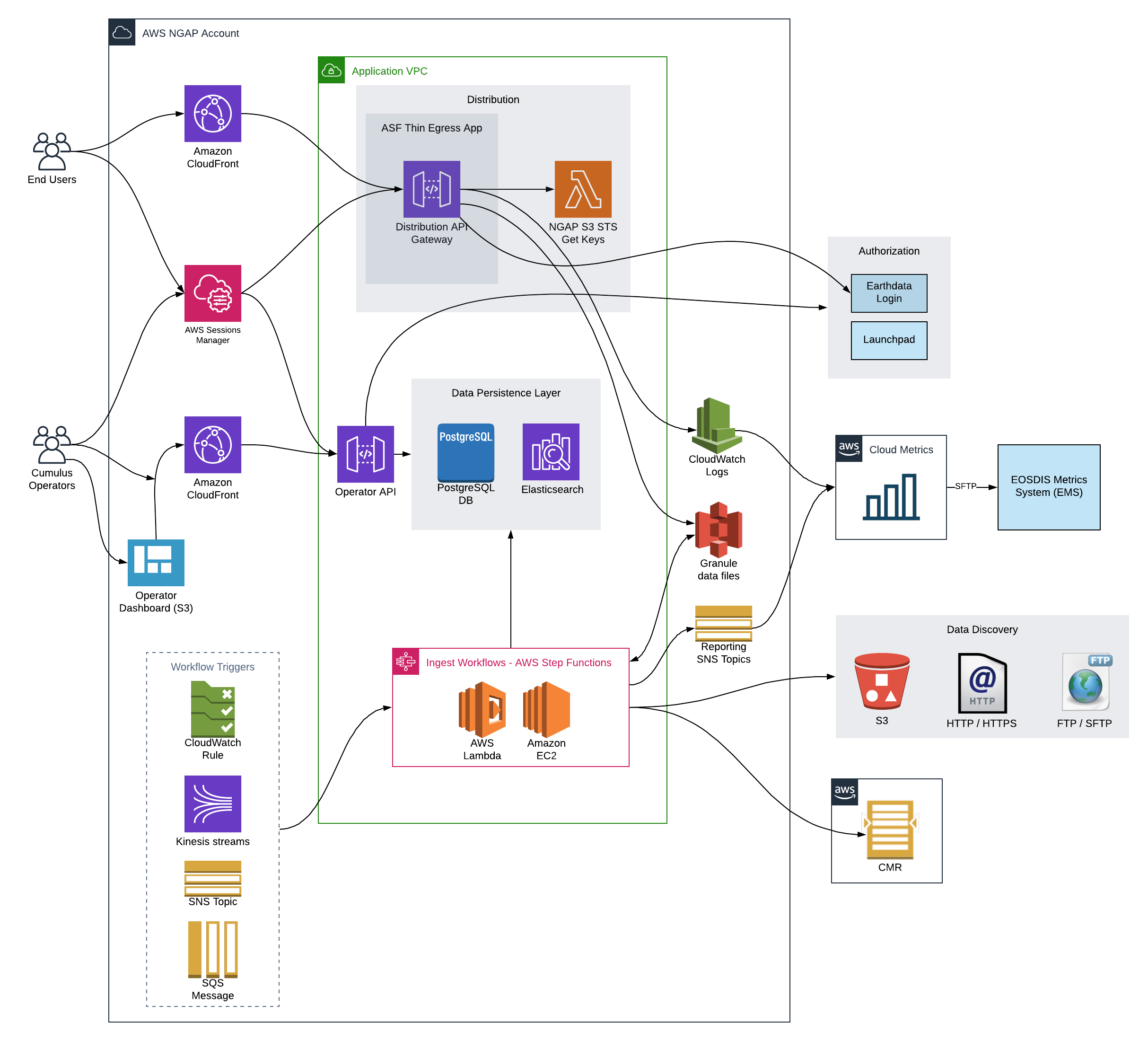
This diagram details all of the major architectural components of a Cumulus deployment.
While the diagram can feel complex, it can easily be digested in several major components:
Data Distribution
End Users can access data via Cumulus's distribution submodule, which includes ASF's thin egress application, this provides authenticated data egress, temporary S3 links and other statistics features.
Data search
End user exposure of Cumulus's holdings is expected to be provided by an external service.
For NASA use, this is assumed to be CMR in this diagram.
Data ingest
Workflows
The core of the ingest and processing capabilities in Cumulus is built into the deployed AWS Step Function workflows. Cumulus rules trigger workflows via either Cloud Watch rules, Kinesis streams, SNS topic, or SQS queue. The workflows then run with a configured Cumulus message, utilizing built-in processes to report status of granules, PDRs, executions, etc to the Data Persistence components.
Workflows can optionally report granule metadata to CMR, and workflow steps can report metrics information to a shared SNS topic, which could be subscribed to for near real time granule, execution, and PDR status. This could be used for metrics reporting using an external ELK stack, for example.
Data persistence
Cumulus entity state data is stored in a set of PostgreSQL compatible database, and is exported to an Elasticsearch instance for non-authoritative querying/state data for the API and other applications that require more complex queries. Currently the entity state data is replicated in DynamoDB and this will be removed in a future release.
Data discovery
Discovering data for ingest is handled via workflow step components using Cumulus provider and collection configurations and various triggers. Data can be ingested from AWS S3, FTP, HTTPS and more.
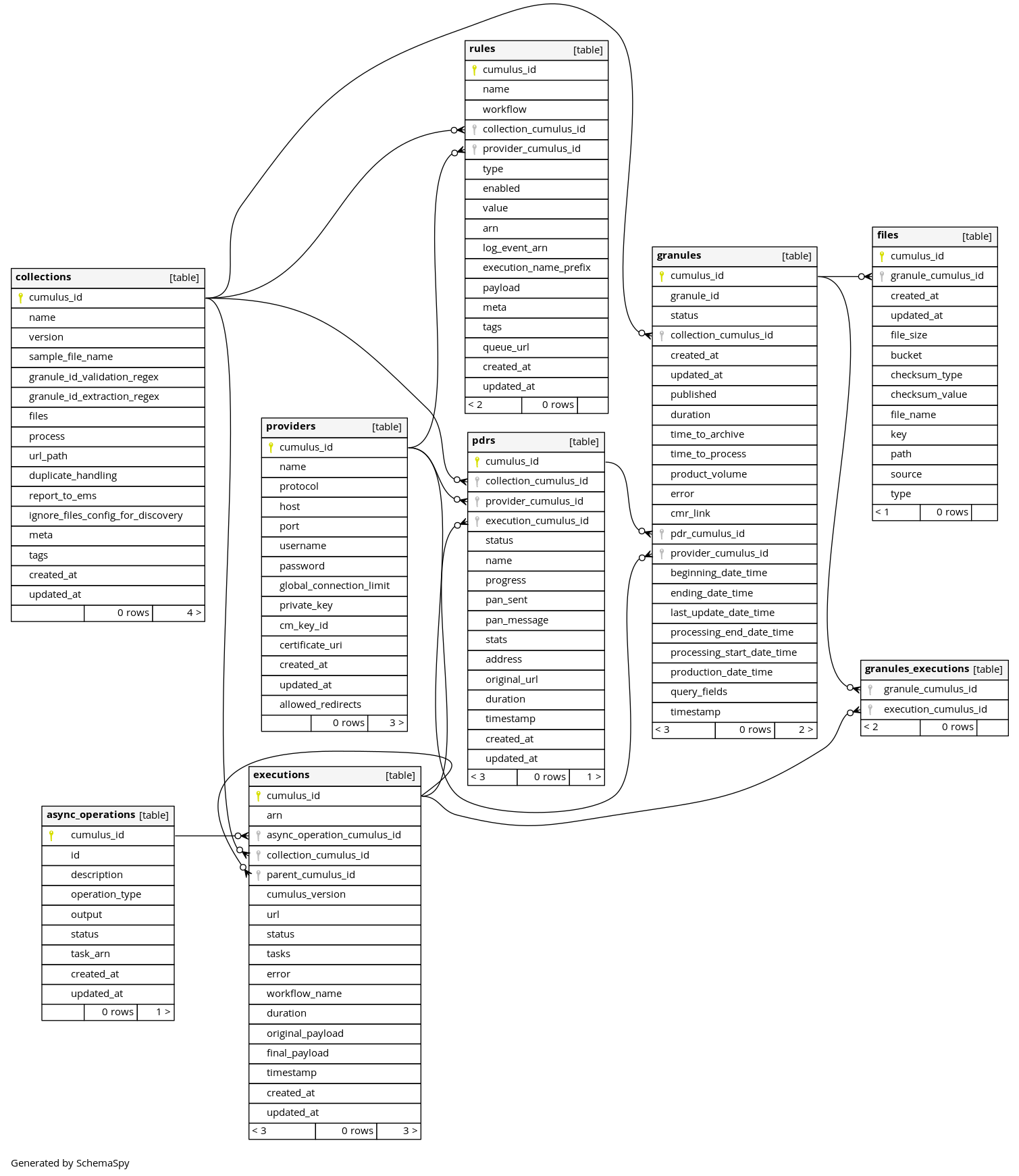
Database
Cumulus utilizes a user-provided PostgreSQL database backend. For improved API search query efficiency Cumulus provides data replication to an Elasticsearch instance. For legacy reasons, Cumulus is currently also deploying a DynamoDB datastore, and writes are replicated in parallel with the PostgreSQL database writes. The DynamoDB replicated tables and parallel writes will be removed in future releases.
PostgreSQL Database Schema Diagram
Maintenance
System maintenance personnel have access to manage ingest and various portions of Cumulus via an AWS API gateway, as well as the operator dashboard.
Deployment Structure
Cumulus is deployed via Terraform and is organized internally into two separate top-level modules, as well as several external modules.
Cumulus
The Cumulus module, which contains multiple internal submodules, deploys all of the Cumulus components that are not part of the Data Persistence portion of this diagram.
Data persistence
The data persistence module provides the Data Persistence portion of the diagram.
Other modules
Other modules are provided as artifacts on the release page for use in users configuring their own deployment and contain extracted subcomponents of the cumulus module. For more on these components see the components documentation.
For more on the specific structure, examples of use and how to deploy and more, please see the deployment docs as well as the cumulus-template-deploy repo .