
| Home → Documentation Home → Miscellaneous Trick Tools → Trick Ops |
|---|
Table of Contents
- Requirements
- Features
- The YAML File
- Learn by Example
- File Comparisons
- Post-Run Analysis
- Defining sets of runs
- Order builds, runs, and analyses
- Where does my output go?
- Other Useful Examples
- The TrickOps Design
- Tips and Best Practices
- MonteCarloGenerationHelper
- TrickOps Helper Class
- More Information
TrickOps
TrickOps is shorthand for "Trick Operations". TrickOps is a python3 framework that provides an easy-to-use interface for common testing and workflow actions that Trick simulation developers and users often run repeatedly. Good software developer workflows typically have a script or set of scripts that the developer can run to answer the question "have I broken anything?". The purpose of TrickOps is to provide the logic central to managing these tests while allowing each project to define how and and what they wish to test. Don't reinvent the wheel, use TrickOps!
TrickOps is not a GUI, it's a set of python modules that you can import that let you build a testing framework for your Trick-based project with just a few lines of python code.
Requirements
python version 3.X and the packages in requirements.txt are required to use TrickOps. Virtual environments make this easy, see the python documentation on virtual environments for information on how to create a python3 virtual environment using the requirements.txt file included here.
Features
TrickOps provides the following features:
- Multiple simultaneous sim builds, runs (with or without valgrind), logged data file comparisons, and post-run analyses
- Automatic project environment file sourcing
- Real-time progress bars for sim builds and runs with in-terminal curses interface
- Exit code management lets users easily define success & failure criteria
- Failed comparisons can optionally generate koviz error reports
- Sims, their runs, comparisons, etc. are defined in a single easy-to-read YAML file which TrickOps reads
The YAML File
The YAML file is a required input to the framework which defines all of the tests your project cares about. This is literally a list of sims, each of which may contain runs, each run may contain comparisons and post-run analyses and so on. Here's a very simple example YAML file for a project with two sims, each having one run:
SIM_spacecraft:
path: sims/SIM_spacecraft
runs:
RUN_test/input.py:
returns: 0
SIM_visiting_vehicle:
path: sims/SIM_visiting_vehicle
runs:
RUN_test/input.py:
returns: 0
Simple and readable, this config file is parsed by PyYAML and adheres to all normal YAML syntactical rules. Additionally the Trick-Workflow expected convention for defining sims, runs, comparisons, etc. is described in the TrickWorkflow docstrings and also summarized in detail below:
globals:
env: <-- optional literal string executed before all tests, ex: ". env.sh"
SIM_abc: <-- required unique name for sim of interest, must start with SIM
path: <-- required SIM path relative to project top level
description: <-- optional description for this sim
labels: <-- optional list of labels for this sim, can be used to get sims
- model_x by label within the framework, or for any other project-defined
- verification purpose
build_args: <-- optional literal args passed to trick-CP during sim build
binary: <-- optional name of sim binary, defaults to S_main_{cpu}.exe
size: <-- optional estimated size of successful build output file in bytes
phase: <-- optional phase to be used for ordering builds if needed
parallel_safety: <-- <loose|strict> strict won't allow multiple input files per RUN dir.
Defaults to "loose" if not specified
runs: <-- optional dict of runs to be executed for this sim, where the
RUN_1/input.py --foo: dict keys are the literal arguments passed to the sim binary
RUN_2/input.py: and the dict values are other run-specific optional dictionaries
RUN_[10-20]/input.py: described in indented sections below. Zero-padded integer ranges
can specify a set of runs with continuous numbering using
[<starting integer>-<ending integer>] notation
returns: <int> <---- optional exit code of this run upon completion (0-255). Defaults
to 0
compare: <---- optional list of <path> vs. <path> comparison strings to be
- a vs. b compared after this run is complete. Zero-padded integer ranges
- d vs. e are supported as long as they match the pattern in the parent run.
- ... All non-list values are ignored and assumed to be used to define
- ... an alternate comparison method in a class extending this one
analyze: <-- optional arbitrary string to execute as job in bash shell from
project top level, for project-specific post-run analysis
phase: <-- optional phase to be used for ordering runs if needed
valgrind: <-- optional string of flags passed to valgrind for this run.
If missing or empty, this run will not use valgrind
non_sim_extension_example:
will: be ignored by TrickWorkflow parsing for derived classes to implement as they wish
Almost everything in this file is optional, but there must be at least one top-level key that starts with SIM and it must contain a valid path: <path/to/SIM...> with respect to the top level directory of your project. Here, SIM_abc represents "any sim" and the name is up to the user, but it must begin with SIM since TrickWorkflow purposefully ignores any top-level key not beginning with SIM and any key found under the SIM key not matching any named parameter above. This design allows for extensibility of the YAML file for non-sim tests specific to a project.
There is no limit to number of SIMs, runs:, compare: lists, valgrind runs: list, etc. This file is intended to contain every Sim and and every sim's run, and every run's comparison and so on that your project cares about. Remember, this file represents the pool of tests, not necessarily what must be tested every time your scripts which use it run.
Learn TrickOps with an Example Workflow that uses this Trick Repository
Included in TrickOps is ExampleWorkflow.py, which sets up a simple "build all sims, run all runs" testing script in less than 20 lines of code! It clones the Trick repo from https://github.com/nasa/trick.git, writes a YAML file describing the sims and runs to test, then uses TrickOps to build sims and run runs in parallel. To see it in action, simply run the script:
cd trick/share/trick/trickops/
./ExampleWorkflow.py
When running, you should see output that looks like this:
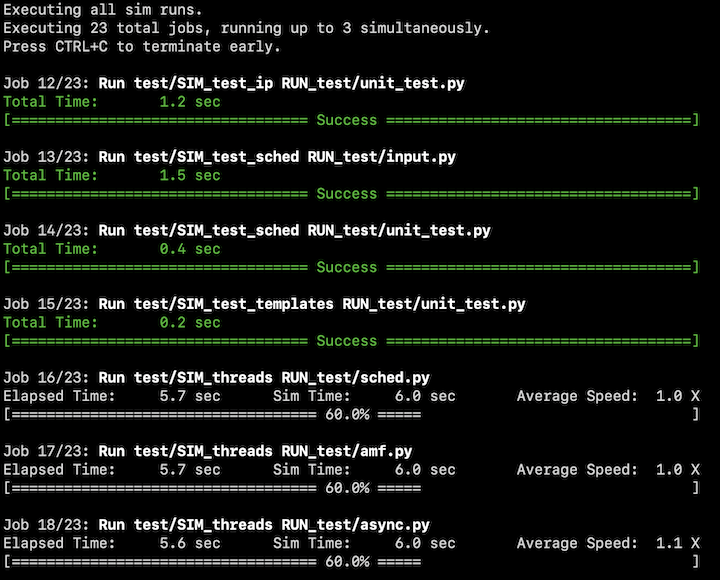
When running this example script, you'll notice that tests occur in two phases. First, sims build in parallel up to three at a time. Then when all builds complete, sims run in parallel up to three at a time. Progress bars show how far along each build and sim run is at any given time. The terminal window will accept scroll wheel and arrow input to view current builds/runs that are longer than the terminal height. Before the script finishes, it reports a summary of what was done, providing a list of which sims and runs were successful and which were not.
Looking inside the script, the code at top of the script creates a yaml file containing a large portion of the sims and runs that ship with trick and writes it to /tmp/config.yml. This config file is then used as input to the TrickWorkflow framework. At the bottom of the script is where the magic happens, this is where the TrickOps modules are used:
from TrickWorkflow import *
class ExampleWorkflow(TrickWorkflow):
def __init__( self, quiet, trick_top_level='/tmp/trick'):
# Real projects already have trick somewhere, but for this example, just clone & build it
if not os.path.exists(trick_top_level):
os.system('cd %s && git clone https://github.com/nasa/trick' % (os.path.dirname(trick_top_level)))
if not os.path.exists(os.path.join(trick_top_level, 'lib64/libtrick.a')):
os.system('cd %s && ./configure && make' % (trick_top_level))
# Base Class initialize, this creates internal management structures
TrickWorkflow.__init__(self, project_top_level=trick_top_level, log_dir='/tmp/',
trick_dir=trick_top_level, config_file="/tmp/config.yml", cpus=3, quiet=quiet)
def run( self):
build_jobs = self.get_jobs(kind='build')
run_jobs = self.get_jobs(kind='run')
builds_status = self.execute_jobs(build_jobs, max_concurrent=3, header='Executing all sim builds.')
runs_status = self.execute_jobs(run_jobs, max_concurrent=3, header='Executing all sim runs.')
self.report() # Print Verbose report
self.status_summary() # Print a Succinct summary
return (builds_status or runs_status or self.config_errors)
if __name__ == "__main__":
sys.exit(ExampleWorkflow(quiet=(True if len(sys.argv) > 1 and 'quiet' in sys.argv[1] else False)).run())
Let's look at a few key parts of the example script. Here, we create a new class arbitrarily named ExampleWorkflow which inherits from TrickWorkflow, which is a class provided by the TrickWorkflow.py module. As part of its class setup, it clones a new trick repo from GitHub and places it in /tmp/. Since '/tmp/trick' provides many example sims and runs, we eat our own dogfood here and use it to represent our project_top_level for example purposes.
from TrickWorkflow import *
class ExampleWorkflow(TrickWorkflow):
def __init__( self, quiet, trick_top_level='/tmp/trick'):
# Real projects already have trick somewhere, but for this example, just clone & build it
if not os.path.exists(trick_top_level):
os.system('cd %s && git clone https://github.com/nasa/trick' % (os.path.dirname(trick_top_level)))
if not os.path.exists(os.path.join(trick_top_level, 'lib64/libtrick.a')):
os.system('cd %s && ./configure && make' % (trick_top_level))
Our new class ExampleWorkflow.py can be initialized however we wish as long as it provides the necessary arguments to it's Base class initializer. In this example, __init__ takes two parameters: trick_top_level which defaults to /tmp/trick, and quiet which will be False unless quiet is found in the command-line args to this script. The magic happens on the very next line where we call the base-class TrickWorkflow initializer which accepts four required parameters:
TrickWorkflow.__init__(self, project_top_level=trick_top_level, log_dir='/tmp/',
trick_dir=trick_top_level, config_file="/tmp/config.yml", cpus=3, quiet=quiet)
The required parameters are described as follows:
project_top_levelis the absolute path to the highest-level directory of your project. The "top level" is up to the user to define, but usually this is the top level of your repository and at minimum must be a directory from which all sims, runs, and other files used in your testing are recursively reachable.log_diris a path to a user-chosen directory where all logging for all tests will go. This path will be created for you if it doesn't already exist.trick_diris an absolute path to the top level directory for the instance of trick used for your project. For projects that use trick as agitsubmodule, this is usually<project_top_level>/trickconfig_fileis the path to a YAML config file describing the sims, runs, etc. for your project. It's recommended this file be tracked in your SCM tool but that is not required. More information on the syntax expected in this file in the The YAML File section above.
The optional parameters are described as follows:
cpustells the framework how many CPUs to use on sim builds. This translates directly toMAKEFLAGSand is separate from the maximum number of simultaneous sim builds.quiettells the framework to suppress progress bars and other verbose output. It's a good idea to usequiet=Trueif your scripts are going to be run in a continuous integration (CI) testing framework such as GitHub Actions, GitLab CI, or Jenkins, because it suppresses allcurseslogic during job execution which itself expectsstdinto exist.
When TrickWorkflow initializes, it reads the config_file and verifies the information given matches the expected convention. If a non-fatal error is encountered, a message detailing the error is printed to stdout and the internal timestamped log file under log_dir. A fatal error will raise RuntimeError. Classes which inherit from TrickWorkflow may also access self.parsing_errors and self.config_errors which are lists of errors encountered from parsing the YAML file and errors encountered from processing the YAML file respectively.
Moving on to the next few important lines of code in our ExampleWorkflow.py script. The def run(self): line declares a function whose return code on run is passed back to the calling shell via sys.exit(). This is where we use the functions given to us by inherting from TrickWorkflow:
build_jobs = self.get_jobs(kind='build')
run_jobs = self.get_jobs(kind='run')
builds_status = self.execute_jobs(build_jobs, max_concurrent=3, header='Executing all sim builds.')
runs_status = self.execute_jobs(run_jobs, max_concurrent=3, header='Executing all sim runs.')
These four lines of code will build all simulations in our config file in parallel up to three at once, followed by running all simulation runs in parallel up to three at once. The get_jobs() function is the easiest way to get a set of jobs from the pool of jobs we defined in our config file of a certain kind. It will return a list of Job instances matching the kind given. For example build_jobs = self.get_jobs(kind='build') means "give me a list of every job which builds a simulation defined in my config file". These Job instances can then be passed as a list to the execute_jobs() function which manages their execution and collection of their return codes and output. execute_jobs will start the list of Jobs given to it, running a maximum of max_concurrent at a time, and returns 0 (False) if all jobs success, 1 (True) if any job failed. kind can be: 'build', 'run', 'valgrind', or 'analysis'.
The last three lines simply print a detailed report of what was executed and manage the exit codes so that ExampleWorkflow.py's return code can be trusted to report pass/fail status to the calling shell in the typical linux style: zero on success, non-zero on failure.
self.report() # Print Verbose report
self.status_summary() # Print a Succinct summary
return (builds_status or runs_status or self.config_errors)
The ExampleWorkflow.py script uses sims/runs provided by trick to exercise some of the functionality provided by TrickOps. This script does not have any comparisons, post-run analyses, or valgrind runs defined in the YAML file, so there is no execution of those tests in this example.
compare: - File vs. File Comparisons
In the TrickWorkflow base class, a "comparison" is an easy way to compare two logged data files via an md5sum compare. Many sim workflows generate logged data when their sims run and want to compare that logged data to a stored off baseline (a.k.a regression) version of that file to answer the question: "has my sim response changed?". TrickOps makes it easy to execute these tests by providing a compare() function at various levels of the architecture which returns 0 (False) on success and 1 (True) if the files do not match.
In the YAML file, the compare: section under a specific run: key defines the comparison the user is interested in. For example consider this YAML file:
SIM_ball:
path: path/to/SIM_ball
runs:
RUN_foo/input.py:
RUN_test/input.py:
compare:
- path/to/SIM_ball/RUN_test/log_a.csv vs. regression/SIM_ball/log_a.csv
- path/to/SIM_ball/RUN_test/log_b.trk vs. regression/SIM_ball/${ENV_VAR}/log_b.trk
In this example, SIM_ball's run RUN_foo/input.py doesn't have any comparisons, but RUN_test/input.py contains two comparisons, each of which compares data generated by the execution of RUN_test/input.py to a stored off version of the file under the regression/ directory relative to the top level of the project. Environment variables may be used when specifying paths to data files. Environment variables are not set by TrickOps, variables must be set before TrickOps is used. The comparisons themselves can be executed in your python script via the compare() function in multiple ways. For example:
# Assuming we're in a python script using TrickWorkflow as a base class and RUN_test/input.py
# has already been executed locally so that logged data exists on disk...
# OPTION 1: Execute compare() at the top level of TrickWorkflow
ret = self.compare() # Execute all comparisons for all runs across all sims
# OPTION 2: Get the sim you care about and execute compare() on only that sim
s = self.get_sim('SIM_ball') # Get the sim we care about
ret = s.compare() # Execute all comparisons for all runs in 'SIM_ball'
# OPTION 3: Get the run you care about and execute compare() at the run level
r = self.get_sim('SIM_ball').get_run('RUN_test/input.py')
ret = r.compare() # Execute all comparisons for run 'RUN_test/input.py'
In all three of these options, ret will be 0 (False) if all comparisons succeeded and 1 (True) if at least one comparison failed. You may have noticed the get_jobs() function does not accept kind='comparison'. This is because comparisons are not Job instances. Use compare() to execute comparisons and get_jobs() with execute_jobs() for builds, run, analyses, etc.
Koviz Utility Functions
When a comparison fails, usually the developer's next step is to look at the differences in a plotting tool. TrickOps provides an interface to koviz, which lets you quickly and easily generate error plot PDFs when a set of comparisons fail. This requires that the koviz binary be on your user PATH and that your koviz version is newer than 4/1/2021. Here are a couple examples of how to do this:
# Assuming we're in a python script using TrickWorkflow as a base class and have
# executed a compare() which has failed...
# OPTION 1: Get all koviz report jobs for all failed comparisons in your YAML file
(koviz_jobs, failures) = self.get_koviz_report_jobs()
# Execute koviz jobs to generate the error plots, up to four at once
if not failures:
self.execute_jobs(koviz_jobs, max_concurrent=4, header='Generating koviz error plots')
# OPTION 2: Get a single koviz report job by providing two directories to have koviz compare
(krj, failure) = self.get_koviz_report_job('path/to/test_data/', 'path/to/baseline_data/')
if not failure:
self.execute_jobs([krj], header='Generating koviz error plots')
If an error is encountered, like koviz or a given directory cannot be found, None is returned in the first index of the tuple, and the error information is returned in the second index of the tuple for get_koviz_report_job(). The get_koviz_report_jobs() function just wraps the singular call and returns a tuple of ( list_of_jobs, list_of_any_failures ). Note that koviz accepts entire directories as input, not specific paths to files. Keep this in mind when you organize how regression data is stored and how logged data is generated by your runs.
analyze: - Post-Run Analysis
The optional analyze: section of a run: is intended to be a catch-all for "post-run analysis". The string given will be transformed into a Job() instance that can be retrieved and executed via execute_jobs() just like any other test. All analyze jobs are assumed to return 0 on success, non-zero on failure. One example use case for this would be creating a jupytr notebook that contains an analysis of a particular run.
Defining sets of runs using [integer-integer] range notation
The yaml file for your project can grow quite large if your sims have a lot of runs. This is especially the case for users of monte-carlo, which may generate hundreds or thousands of runs that you may want to execute as part of your TrickOps script. In order to support these use cases without requiring the user to specify all of these runs individually, TrickOps supports a zero-padded [integer-integer] range notation in the run: and compare: fields. Consider this example yaml file:
SIM_many_runs:
path: sims/SIM_many_runs
runs:
RUN_[000-100]/monte_input.py:
returns: 0
compare:
sims/SIM_many_runs/RUN_[000-100]/log_common.csv vs. baseline/sims/SIM_many_runs/log_common.csv
sims/SIM_many_runs/RUN_[000-100]/log_verif.csv vs. baseline/sims/SIM_many_runs/RUN_[000-100]/log_verif.csv
In this example, SIM_many_runs has 101 runs. Instead of specifying each individual run (RUN_000/, RUN_001, etc), in the yaml file, the [000-100] notation is used to specify a set of runs. All sub-fields of the run apply to that same set. For example, the default value of 0 is used for returns:, which also applies to all 101 runs. The compare: subsection supports the same range notation, as long as the same range is used in the run: named field. Each of the 101 runs shown above has two comparisons. The first compare: line defines a common file to be compared against all 101 runs. The second compare: line defines run-specific comparisons using the same [integer-integer] sequence. Note that when using these range notations zero-padding must be consistent, the values (inclusive) must be non-negative, and the square bracket notation must be used with the format [minimum-maximum].
phase: - An optional mechanism to order builds, runs, and analyses
The yaml file supports an optional parameter phase: <integer> at the sim and run level which allows the user to easily order sim builds, runs, and/or analyses, to suit their specific project constraints. If not specified, all sims, runs, and analyses, have a phase value of 0 by default. Consider this example yaml file with three sims:
SIM_car:
path: sims/SIM_car
SIM_monte:
path: sims/SIM_monte
runs:
RUN_nominal/input.py --monte-carlo: # Generates the runs below
phase: -1
MONTE_RUN_nominal/RUN_000/monte_input.py: # Generated run
MONTE_RUN_nominal/RUN_001/monte_input.py: # Generated run
MONTE_RUN_nominal/RUN_002/monte_input.py: # Generated run
MONTE_RUN_nominal/RUN_003/monte_input.py: # Generated run
MONTE_RUN_nominal/RUN_004/monte_input.py: # Generated run
# A sim with constraints that make the build finnicky, and we can't change the code
SIM_external:
path: sims/SIM_external
phase: -1
runs:
RUN_test/input.py:
returns: 0
Here we have three sims: SIM_car, SIM_monte, and SIM_external. SIM_car and SIM_monte have the default phase of 0 and SIM_external has been assigned phase: -1 explicitly. If using non-zero phases, jobs can be optionally filtered by them when calling helper functions like self.get_jobs(kind, phase). Some examples:
build_jobs = self.get_jobs(kind='build') # Get all build jobs regardless of phase
build_jobs = self.get_jobs(kind='build', phase=0) # Get all build jobs with (default) phase 0
build_jobs = self.get_jobs(kind='build', phase=-1) # Get all build jobs with phase -1
build_jobs = self.get_jobs(kind='build', phase=[0, 1, 3]) # Get all build jobs with phase 0, 1, or 3
build_jobs = self.get_jobs(kind='build', phase=range(-10,11)) # Get all build jobs with phases between -10 and 10
This can be done for runs and analyses in the same manner:
run_jobs = self.get_jobs(kind='run') # Get all run jobs regardless of phase
run_jobs = self.get_jobs(kind='run', phase=0) # Get all run jobs with (default) phase 0
# Get all run jobs with all phases less than zero
run_jobs = self.get_jobs(kind='run', phase=range(TrickWorkflow.allowed_phase_range['min'],0))
# Get all analysis jobs with all phases zero or greater
an_jobs = self.get_jobs(kind='analysis', phase=range(0, TrickWorkflow.allowed_phase_range['max'+1]))
Note that since analysis jobs are directly tied to a single named run, they inherit the phase value of their run as specfied in the yaml file. In other words, do not add a phase: section indented under any analyze: section in your yaml file.
It's worth emphasizing that the specfiication of a non-zero phase in the yaml file, by itself, does not affect the order in which actions are taken. It is on the user of TrickOps to use this information to order jobs appropriately. Here's an example in code of what that might look for the example use-case described by the yaml file in this section:
first_build_jobs = self.get_jobs(kind='build', phase=-1) # Get all build jobs with phase -1 (SIM_external)
second_build_jobs = self.get_jobs(kind='build', phase=0) # Get all build jobs with phase 0 (SIM_car & SIM_monte)
first_run_jobs = self.get_jobs(kind='run', phase=-1) # Get all run jobs with phase -1 (RUN_nominal/input.py --monte-carlo)
second_run_jobs = self.get_jobs(kind='run', phase=0) # Get all run jobs with phase 0 (All generated runs & RUN_test/input.py)
# SIM_external must build before SIM_car and SIM_monte, for project-specific reasons
builds_status1 = self.execute_jobs(first_build_jobs, max_concurrent=3, header='Executing 1st phase sim builds.')
# SIM_car and SIM_monte can build at the same time with no issue
builds_status2 = self.execute_jobs(second_build_jobs, max_concurrent=3, header='Executing 2nd phase sim builds.')
# SIM_monte's 'RUN_nominal/input.py --monte-carlo' generates runs
runs_status1 = self.execute_jobs(first_run_jobs, max_concurrent=3, header='Executing 1st phase sim runs.')
# SIM_monte's 'MONTE_RUN_nominal/RUN*/monte_input.py' are the generated runs, they must execute after the generation is complete
runs_status2 = self.execute_jobs(second_run_jobs, max_concurrent=3, header='Executing 2nd phase sim runs.')
Astute observers may have noticed that SIM_external's RUN_test/input.py technically has no order dependencies and could execute in either the first or second run job set without issue.
A couple important points on the motivation for this capability:
- Run phasing was primarly developed to support testing monte-carlo and checkpoint sim scenarios, where output from a set of scenarios (like generated runs or dumped checkpoints) becomes the input to another set of sim scenarios.
- Sim phasing exists primarly to support testing scenarios where sims are poorly architectured or immutable, making them unable to be built independently.
Where does the output of my tests go?
All output goes to a single directory log_dir, which is a required input to the TrickWorkflow.__init__() function. Sim builds, runs, comparisons, koviz reports etc. are all put in a single directory with unique names. This is purposeful for two reasons:
- When a failure occurs, the user can always find verbose output in the same place
- Easy integration into CI artifact collection mechanisms. Just collect
log_dirto get all verbose output for successful and failed tests alike.
Logging for the TrickWorfklow itself, including a list of all executed tests will automatically be created in <log_dir>/log.<timestamp>.txt
Other Useful Examples
# Assuming you are within the scope of a class inheriting from TrickWorkflow ...
self.report() # Report colorized verbose information regarding the pool of tests
s = self.status_summary() # Print a succinct summary regarding the pool of tests
myvar = self.config['myvar']) # Access custom key 'myvar' in YAML file
tprint("My important msg") # Print to the screen and log a message internally
# Define my own custom job and run it using execute_jobs()
myjob = Job(name='my job', command='sleep 10', log_file='/tmp/out.txt', expected_exit_status=0)
self.execute_jobs([myjob])
Regarding the Design: Why do I have to write my own script?
You may be thinking, "sure it’s great that it only takes a few lines of python code to use this framework, but why isn’t TrickOps just a generic cmdline interface that I can use? Why isn't it just this?":
./trickops --config project_config.yml
This is purposeful -- handling every project-specific constraint is impossible. Here's a few examples of project-specific constraints that make a generic catch-all ./trickops script very difficult to implement:
- "I want to fail testing on SIM_a, but SIM_b build is allowed to fail!"
- Solution: Project-specific script defines success with
sys.exit(<my_critera>)
- Solution: Project-specific script defines success with
- "I need to add project-specific key-value pairs in the YAML file!"
- Solution: Project specific script reads
self.configto get these
- Solution: Project specific script reads
- "I don’t want to use
koviz, I want to generate errors plots with matlab!"- Solution: Project specific script extends
class Comparison
- Solution: Project specific script extends
- "I have a pre-sim-build mechanism (like
matlab) that complicates everything!"- Solution: Project specific script runs
execute_jobs()on customJobs before normal sim builds are executed
- Solution: Project specific script runs
Tips and Best Practices
- Commit your YAML file to your project. What gets tested will change over time, you want to track those changes.
- If your project requires an environment, it's usually a good idea to track a source-able environment file that users can execute in their shell. For example, if
myproject/.bashrccontains your project environment, you should addsource .bashrc ;to theenv:section ofglobalsin your YAML config file. This tellsTrickWorkflowto addsource .bashrc ;before everyJob()'scommand. - Make sure you execute your tests in an order that makes sense logically. The TrickOps framework will not automatically execute a sim build before a sim run for example, it's on the user to define the order in which tests run and which tests are important to them.
- Be cognizant of how many CPUs you've passed into
TricKWorkflow.__init__and how many sims you build at once. Each sim build will use thecpusgiven toTrickWorkflow.__init__, so if you are building 3 sims at once each with 3 cpus you're technically requesting 9 cpus worth of build, so to speak. - If
TrickWorkflowencounters non-fatal errors while verifying the content of the given YAML config file, it will add those errors to the internalself.config_errorslist of strings. If you want your script to return non-zero on any non-fatal error, includeself.config_errorsin the criteria used forsys.exit(<success_criteria>). Similar recommendation forself.parsing_errorswhich contains all errors found while parsing the YAML file. - Treat the YAML file like your project owns it. You can store project-specific information and retrieve that information in your scripts by accessing the
self.configdictionary. Anything not recognized by the internal validation of the YAML file is ignored, but that information is still provided to the user. For example, if you wanted to store a list of POCS in your YAML file so that your script could print a helpful message on error, simply add a new entryproject_pocs: email1, email2...and then access that information viaself.config['project_pocs']in your script.
MonteCarloGenerationHelper - TrickOps Helper Class for MonteCarloGenerate.sm users
TrickOps provides the MonteCarloGenerationHelper python module as an interface between a sim using the MonteCarloGenerate.sm (MCG) sim module and a typical Trick-based workflow. This module allows MCG users to easily generate monte-carlo runs and execute them locally or alternatively through an HPC job scheduler like SLURM. Below is an example usage of the module. This example assumes:
- The using script inherits from or otherwise leverages
TrickWorkflow, giving it access toself.execute_jobs() SIM_Ais already built and configured with theMonteCarloGenerate.smsim moduleRUN_mc/input.pyis configured with to generate runs when executed, specifically thatmonte_carlo.mc_master.generate_dispersions == monte_carlo.mc_master.active == Truein the input file.
# Instantiate an MCG helper instance, providing the sim and input file for generation
mgh = MonteCarloGenerationHelper(sim_path="path/to/SIM_A", input_path="RUN_mc/input.py")
# Get the generation SingleRun() instance
gj = mgh.get_generation_job()
# Execute the generation Job to generate RUNS
ret = self.execute_jobs([gj])
if ret == 0: # Successful generation
# Get a SLURM sbatch array job for all generated runs found in monte_dir
# SLURM is an HPC (High-Performance-Computing) scheduling tool installed on
# many modern super-compute clusters that manages execution of a massive
# number of jobs. See the official documentation for more information
# Slurm: https://slurm.schedmd.com/documentation.html
sbj = mgh.get_sbatch_job(monte_dir="path/to/MONTE_RUN_mc")
# Execute the sbatch job, which queues all runs in SLURM for execution
# Use hpc_passthrough_args ='--wait' to block until all runs complete
ret = self.execute_jobs([sbj])
# Instead of using SLURM, generated runs can be executed locally through
# TrickOps calls on the host where this script runs. First get a list of
# run jobs
run_jobs = mgh.get_generated_run_jobs(monte_dir="path/to/MONTE_RUN_mc")
# Then execute all generated SingleRun instances, up to 10 at once
ret = self.execute_jobs(run_jobs, max_concurrent=10)
Note that the number of runs to-be-generated is configured somewhere in the input.py code and this module cannot robustly know that information for any particular use-case. This is why monte_dir is a required input to several functions - this directory is processed by the module to understand how many runs were generated.
send_hs - TrickOps Helper Class for Parsing Simulation Diagnostics
Each Trick simulation run directory contains a number of Trick-generated metadata files, one of which is the send_hs file which represents all output during the simulation run sent through the Trick "(h)ealth and (s)tatus" messaging system. At the end of the send_hs message, internal diagnostic information is printed by Trick that looks a lot like this:
|L 0|2024/11/21,15:54:20|myworkstation| |T 0|68.955000|
REALTIME SHUTDOWN STATS:
ACTUAL INIT TIME: 42.606
ACTUAL ELAPSED TIME: 55.551
|L 0|2024/11/21,15:54:20|myworkstation| |T 0|68.955000|
SIMULATION TERMINATED IN
PROCESS: 0
ROUTINE: Executive_loop_single_thread.cpp:98
DIAGNOSTIC: Reached termination time
SIMULATION START TIME: 0.000
SIMULATION STOP TIME: 68.955
SIMULATION ELAPSED TIME: 68.955
USER CPU TIME USED: 55.690
SYSTEM CPU TIME USED: 0.935
SIMULATION / CPU TIME: 1.218
INITIALIZATION USER CPU TIME: 42.783
INITIALIZATION SYSTEM CPU TIME: 0.901
SIMULATION RAM USAGE: 1198.867MB
(External program RAM usage not included!)
VOLUNTARY CONTEXT SWITCHES (INIT): 792
INVOLUNTARY CONTEXT SWITCHES (INIT): 187
VOLUNTARY CONTEXT SWITCHES (RUN): 97
INVOLUNTARY CONTEXT SWITCHES (RUN): 14
The information provided here is a summary of how long the simulation ran, in both wall-clock time, and cpu time, both for initialization and run-time, and other useful metrics like how much peak RAM was used during run-time execution. Tracking this information can be useful for Trick-using groups so TrickOps provides a utility class for parsing this data. Here's an example of how you might use the send_hs module:
import send_hs # Import the module
# Instantiate a send_hs instance, reading the given send_hs file
shs = send_hs.send_hs("path/to/SIM_A/RUN_01/send_hs")
start_time = shs.get('SIMULATION START TIME') # Get the value of sim start time
stop_time = shs.get('SIMULATION STOP TIME') # Get the value of sim stop time
realtime_ratio = shs.get('SIMULATION / CPU TIME') # Get the realtime ratio (how fast the sim ran)
# Instead of getting diagnostics individually, you can ask for the full dictionary
diagnostics = shs.get_diagnostics()
# Print the RAM usage from the dictionary
print(diagnostics['SIMULATION RAM USAGE'])
Plotting this data for regression scenarios can be quite useful - a lot of groups would want to know if the sim slowed down significantly and if so, when in the history this occurred. If you are already invested in Jenkins CI, you might be interested in using the send_hs module in conjunction with the Jenkins plot plugin. Here's an example of what tracking sim realtime ratio over time looks like in a workflow with about 15 regression scenarios all shown on a single plot:
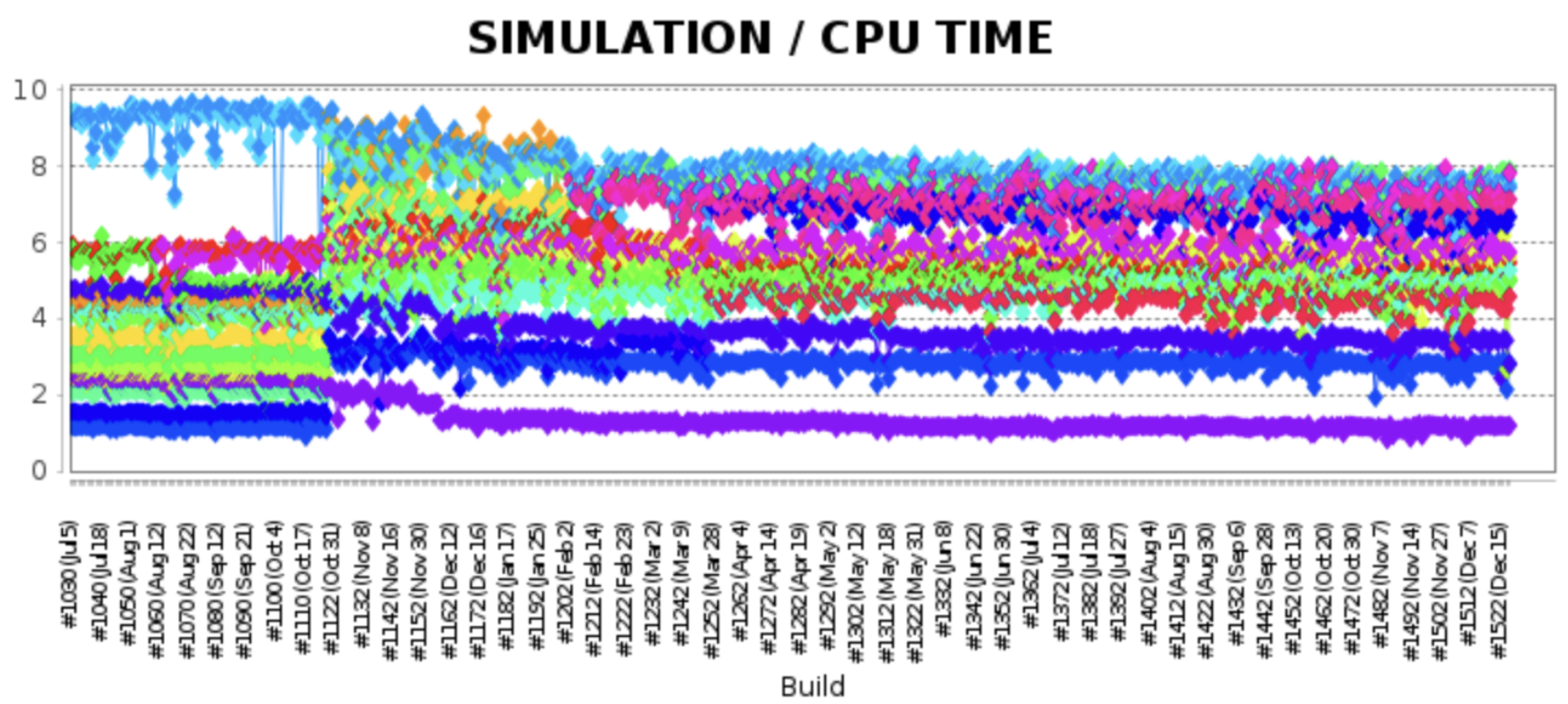
More Information
A lot of time was spent adding python docstrings to the modules in the trickops/ directory and tests under the trickops/tests/. This README does not cover all functionality, so please see the in-code documentation and unit tests for more detailed information on the framework capabilities.